Распознавание речи в рамках проблемы искусственного интеллекта.

все равно, здорово получаются эти пузыри. А что? Так и назову:
пузыри. Нет, наверное, лучше "полости". Полости малянова.
"М-полости". Гм...»
(Аркадий и Борис Стругацкие. За миллиард лет до конца света.)
Примечание.
Данная статья в её надлежащем виде будет постепенно оформляться. Пока же в первую очередь в ней появятся материалы, необходимые для обсуждения данной темы на форуме Gotai.net.
Постановка задачи.
Распознавание голоса, как задача для коммерческого использования решена в основном в компании Google[1]. Чтобы увидеть как это происходит надо зайти с помощью браузера Chrome. Голосовые сообщения распознаются без предварительного обучения. Помеховая обстановка и качество микрофонной записи должны при этом быть на хорошем уровне. Задача распознавания слитной речи, на мой взгляд, пока не имеет таких же результатов и выполняется с применением интерактивных методов[2].
Все, что делается на данный момент в этой области условно назовем классическим подходом. Что это значит? Задача распознавания представляется прежде всего как задача построения некоего фильтра. Пусть он будет сколь угодно сложный, с обучением, с подключением алфавита, на основе которого делается фонетическое предсказание и т.д. Все это классический подход.
Как можно поставить задачу распознавания иначе? Прежде всего отмечу, что в классическом подходе есть некий уровень математизации: это и Фурье-преобразование, оконные фильтры и реализация предобработки цифровыми фильтрами и нейронные сети и многое другое. И меня всегда удивляла особенность человека слышать и узнавать ктО говорит и чтО говорится. И при этом совершеннейшая тайна в том, где и как подобные математические методы реализованы? И есть ли они? Можно ли найти способ реализовать компьютерную модель так, чтобы в процессе обучения все необходимые способы фильтрации и распознавания речевого потока выстраивались бы постепенно, а не закладывались бы программистом заранее. Конечно же что – то должно быть заложено априорно. Например, частотное преобразование в ухе происходит и это описано в замечательной книге Ирины Алдошиной «Основы психоакустики[3]»
Для того чтобы приблизиться к пониманию того, можно ли подобную задачу реализовать необходимо внимательно изучить голосовой поток, и понять на какие составляющие элементы его разложить. Мне представляется, что именно со спектром, а не с амплитудной реализацией АЦП надо иметь дело. Об этом пишут многие[4].
Инструментарий для исследования.
Для изучения речевого потока предлагается программа DFTV, написанная на Delphi7 без привлечения специальных компонентов. Программа не для коммерческого использования, с исходниками, поэтому все ошибки и не развитый интерфейс придется принять как есть.
Вначале необходимо описать какое преобразование происходит со звуком и с чем в итоге работает программа.
- Частота дискретизации(Hz): 16000;
- Количество значений в кадре: 640;
- Количество гармоник: 256/(6375Hz);
- Разрешение по гармоникам: 25(Hz);
- Разрядность АЦП 16 бит;
- Амплитудная реализация звука (-32768..32767) тип smallint;
- Время записи(ms): 2000;
- Длительность кадра(ms): 40;
- Количество кадров: 50;
В каждом кадре реализуется функция амплитуд спектра. Всего в итоге получается массив с размерностью 50 Х 256 значений. Каждое значение типа byte (0..255).
Если подключен микрофон, то при запуске программы появится амплитудная реализация и спектральная. Уровень микрофона в программе не регулируется, это надо делать средствами операционной системы. Можно так же использовать шумоподавление, устранение реверберации и прочие функции, если таковые имеются на звуковой карте.
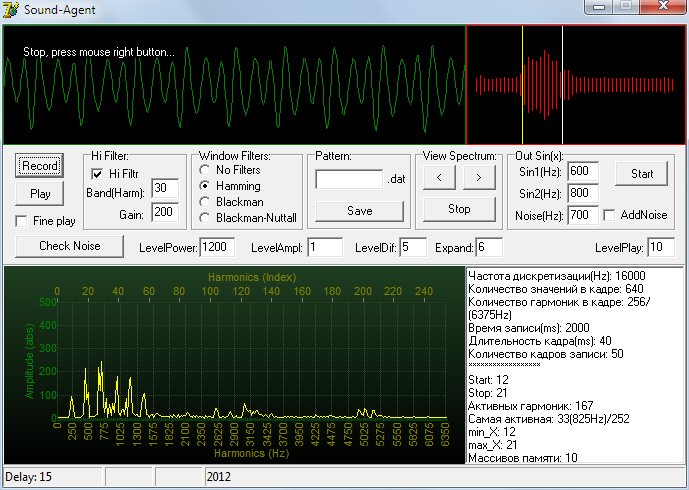
Рис. 1
Вначале надо установить уровень шума кнопкой Check Noise. Соответствующее абстрактное число появится в поле LevelPower. Его так же можно установить вручную. Если вы произносите фразу и она отображается в верхнем графике, то можно нажать кнопку Record. Запись осуществляется в течении 2 секунд. В правом верхнем углу появится огибающая сигнала, которая на основе уровня шума будет выделена вертикальными линиями. Этих линий может быть несколько по количеству характерных фонемных фрагментов. В правом нижнем углу в текстовом окне появятся некоторые характеристики.
График гармоник можно масштабировать по X и по Y. Это обычный компонент Chart. Кто не знаком, скажу, что можно выделять область на этом графике мышкой с нажатой левой кнопкой, делая движение с левого верхнего угла в правый нижний. Возврат в исходный масштаб производится обратным движением. Удерживая нажатой правую копку мыши можно сдвигать картинку во все стороны.
Секция View Spectrum позволяет покадрово рассматривать реализацию гармоник. Всего кадров 50. При этом будут показаны локальные максимумы спектральной функции, которые в дальнейшем будут использоваться для вывода сигнала в режиме Play. Кнопка Stop в этой секции возвращает программу в обычный режим.
Кнопка Play проигрывает весь массив данных. О нем будет сказано позже. Галочка Fine Play позволит отсечь те области огибающей, которые ниже шумового порога, это актуально только при воспроизведении.
Поле LevelPLay - громкость при воспроизведении.
Все уровни имеют отношение не к амплитудной реализации после АЦП, а к спектральной функции:
Level Ampl – уровень, ниже которого гармоника не записывается.
LevelDif- уровень первой производной, выше которого учитывается локальный максимум.
Expand – некий уровень, который определяет динамический диапазон, в котором вычисляются амплитуды гармоник. Малое его числовое значение включает шумы, большое значение отсекает шумы.
Секция Hi Filter – включает фильтр верхних частот, полоса среза определяется полем Band(Harm) в гармониках, усиление в полосе определяется полем Gain.
Если не вдаваться в описанные выше подробности этих параметров, то можно сказать, что манипулируя только LevelDif, Expand и Hi Filtr можно подобрать для разных микрофонов приемлемое воспроизведение голосового сообщения.
Секция Filters for Record позволяет оценить работу оконных фильтров.
Секция Out Sin(x) – включает гармонические сигналы и шум во время записи.

Левое окно – текущая голосовая реализация, правое – паттерн, который можно вызвать соответствующей командой Файл + Загрузить образец из файла.
Sсale Y масштаб.
По оси X – номера кадров.
По оси Y – номера гармоник и частоты.
Max View – если выбран этот параметр, то можно увидеть как распределяются локальные максимумы спектральной функции в каждом кадре.
Binarization – режим отображения в бинарном виде. Выставляется уровень и нажимается Apply.
Compare – простое сравнение двух изображений, где совпадения индицируются. Совершенно не информативно.
Correlation – покадровая корреляционная оценка в процентах по методу Пирсона[5].
Осуществляется не по всему массиву, а на основе выделенной огибающей. Именно поэтому важно, чтобы уровень шума LevelPower был выбран так, чтобы вся фраза оценивалась бы минимальным количеством линий, как это показано на огибающей на Рис1.
Что представляет из себя массив цифр после нажатия кнопки Correlation?
На основе анализа огибающей и уровня LevelPower есть начальный кадр у данных в левом окне и начальный кадр в паттерне. На Рис.1 в текстовом окне эти два события обозначены как Start:12 и Stop: 21. Кадр №12 текущей реализации и начальный кадр паттерна анализируются и в результате получается коэффициент корреляции в процентах. Это самое первое число в строке №1. Количество цифр в строке равно количеству кадров текущей реализации. Последняя цифра в строке - их среднее значение.
Если вместо значений гармоник взять разницу между гармониками в соседних кадрах и провести те же операции, то получится еще три строки:
- Строка №2 DataUp[n][k]:=Data[n][k] - Data[n-1][k+1];
- Строка №3 DataRight[n][k]:=Data[n][k] - Data[n-1][k];
- Строка №4 DataDown[n][k]:=Data[n][k] - Data[n-1][k-1];
Где n-кадр, k- гармоника, Data[n][k] – массив амплитуд гармоник.
И так. Для оценки похожести текущего слова с паттерном, записанным заранее, нужно брать во внимание среднее значение в первой строке. Хорошим совпадением можно считать значение коэффициента корреляции больше 50%. Запись паттерна и последующая корреляционная оценка должна происходить при одинаковых уровнях, их значения сильно влияют на результат. Прежде, чем записывать паттерны, необходимо найти приемлемое соотношение уровней. Критерием для этого может служить субъективная оценка звучания, без сильных помех.
Выводы.
- Самый интересный результат для меня это то, что массив данных 50X256 точек при обратном воспроизведении образует звучание, которое распознается человеком. Распознается ктО и чтО говорит. Надо дополнить, что на самом деле не все 256 гармоник информативны, поэтому массив избыточен по вертикале. Да, и по горизонтали среднее слово меньше 2 секунд. Массив при обратном воспроизведении формировался не на основе всех 256 гармоник, а только тех, которые составляли локальные максимумы в течении кадра. Это первое. Второе – никакой информации о фазе синусов не использовалось. Да, качество воспроизведения не такое, как у движков в SAPI 5, но ведь и задача стоит иная – распознавание. И поэтому можно сделать вывод, что в массиве данных 50X256 есть все необходимое для распознавания. Некие преобразования над массивом были сделаны, например огибающая, которая сама по себе тоже информативна, но она была получена из того же массива без привлечения сторонней информации.
- Корреляционный метод необходим, но не достаточен. Звучание похожих слов оценивается как 50% -е совпадение.
- Оценка коэффициентов корреляции разностных значений гармоник мало информативна, тем более их среднее.
Дальнейшее направление, что можно сделать классическим способом.
- Над огибающей так же можно сделать спектральное преобразование. Это может быть поинтересней, чем кепстральные коэффициенты[6].
- Интересно, как показывают некоторые авторы[7], применить к кадрам фильтр Калмана[8]. И на этой основе распознавать фонемы.
- Ну, и нейронные сети никто не отменял.
- В отличие от распознавания обычного изображения, сонарная картина, которая показана на Рис.2, имеет три инвариантных преобразования. Слово можно произнести быстро или медленно и с разным тоном. Это отражается на сонарной картине, как изменение по оси X и Y, соответственно. Поэтому можно сделать этапы предварительного масштабирования паттерна в процессе корреляционного анализа. Громкость произнесенного слова так же влияет на корреляционные коэффициенты, поэтому можно применить нормализацию по амплитуде гармоник.
- Интересные результаты может дать метод бинаризации. На его основе можно получить все данные для нормализации изображения по X и Y. А корреляционную обработку можно делать для каждого слоя, в этом случае вычисление коэффициента корреляции вырождается в обычное совпадение.
- Метод распознавания с использованием паттернов может потребовать значительной памяти и быстродействия, если запоминать слова. Поэтому многие авторы предлагают использовать распознавание фонем. Библиотека фонем может быть значительно меньше по размеру.
Немного об ином пути.
На данный момент я предложу гипотезу, реализация которой только наметилась. Если рассматривать распознавание, как конечную задачу модели, то в этом прежде всего и есть суть условного классического метода. Но можно предположить, что распознавание это всего навсего действие, необходимое для реализации целевой функции. Как можно обозначить такую целевую функцию? Об этом уже не раз говорилось на форуме:
http://www.gotai.net/forum/Default.aspx?postid=57100#57100
Целевая функция системы это поиск в непрерывном информационном потоке новизны.
Но пока мы не будем вдаваться в рассуждения о том, что поток, если это не белый шум, имеет структуру, которая в дальнейшем может быть отражена в структуре модели. На данном этапе ставится задача оценить сложность программной реализации памяти первого уровня, оценить объем этой памяти и скорость манипуляции данными при сравнении.
Что из себя представляет речевой поток? В рамках представленной программы – это непрерывное чередование кадров. В данном случае кадр, содержащий реализацию амплитуд гармоник, - будет самым низкоуровневым кластером. Фонема будет множеством кадров. Слово – множество фонем. Фраза – множество слов. Абстрактное понятие описывается множеством фраз. Пять кластеров. Каждому кластеру соответствует свой уровень памяти. Каждый уровень реализует целевую функцию. В рамках проблемы искусственного интеллекта в данной статье можно ограничиться узкой задачей на уровне фонем. Пусть задача распознавания фонем будет определять конечную структуру модели. Это будет означать, что когда любой человек произносит слитную речь, модель должна определить все фонемы и их чередование. Это цель, а пока предварительные результаты.
Рассмотрим самый низкий уровень.
Параметры кластера: длительность – 40 мс, количество значений – 256, динамический диапазон 0..255. Таким образом кадр можно представить в виде набора двухбайтовых значений: старший байт – номер гармоники, младший – амплитуда. Теоретически размер этого набора огромен, но практически его можно оценить в весьма приемлемую цифру. Когда производится запись в программе, то в текстовом поле выводится количество активных гармоник (см. Рис 1). И это число менее тысячи. И так же, это число активных гармоник не в одном кадре, а во всей фразе.
Дальнейшее описание может утомить, так как сложно описать взаимодействие динамических массивов и их индексы. Но я попытаюсь, памятуя о том, что есть тексты программы, они могут больше сказать, особенно в режиме отладки. Скажу честно, что сам, работая в дебагере, распрямил себе не одну извилину…
И так, можно описать первый уровень памяти (см. модуль UnitMem):
type Tmem = array of word;type THarmAmpl = array of word;
type TmemLevelData = array of THarmAmpl;
type
private
public
Data: TmemLevelData;
Same: array of array[0..1] of word;
SortNum: array [0..DFT_kmax-1] of Tmem;
size: TAgentParam
constructor Create(level:TAgentParam);
procedure Sleep;
procedure AddData(indat: TmemLevelData; start,stop:integer);
end;
Data – динамический массив упакованных значений:
K:=Hi(Data[n][k]) – номер гармоники;A:=Lo(Data[n][k]) – амплитуда в диапазоне 0..255;
Кадр может теоретически содержать максимум 255 таких значений. При реализации процесса записи массив Data по очереди заполняется неповторяющимися кадрами. Поясню так же, что сортировать и перемещать такой массив не правильно. Этот массив только пополняется новыми фрагментами.
Сравнивать имеет смысл только те массивы, которые имеют одинаковый размер. Чтобы не перебирать весь массив Data при сравнении существует массив SortNum. По сути это 256, по числу гармоник, динамических массивов. Он заполняется синхронно с массивом Data.
Значение этого массива соответствует индексу массива Data.
Вот фрагмент после нескольких записей:
SortNum = ((), (), (), (), (), (), (), (), (), (), (), (8), (3), (5), (2), (0, 6, 9), (1, 4), (7)…);
Data = ((1372, 2324, 3615, 4894, 5926, 7295, 8577, 9602, 10632, 11130, 13085, 16651, 20237, 22552, 26120), (271, 1409, 3863, 5162, 6480, 7467, 7986, 9177, 9853, 11338, 11796, 13077, 13843, 14860, 15632, 22027), (1626, 2864, 4379, 7229, 8554, 9241, 10094, 11304, 13837, 15633, 19723, 21769, 25609, 27150), (1691, 2906, 4386, 7246, 8756, 10100, 11556, 12296, 15888, 21775, 23052, 28170), (523, 1460, 2852, 4143, 4626, 5789, 7010, 8386, 9926, 11137, 12297, 13597, 14856, 16654, 19215, 22029), (1353, 2582, 3867, 4914, 6277, 7481, 8824, 9877, 11435, 13603, 17417, 23055, 27406), (1329, 2319, 4908, 5945, 7180, 8069, 8605, 9522, 10594, 11555, 13154, 15373, 19981, 21257, 26120), (1345, 2339, 3600, 4649, 5924, 8379, 9487, 10519, 12043, 12832, 14347, 15425, 16654, 17677, 18703, 24615, 37385), (1340, 2335, 3609, 4639, 5652, 8230, 8718, 10768, 14092, 15627, 19213), (261, 1345, 3621, 4889, 6033, 7264, 8341, 9653, 10950, 11544, 12058, 13067, 16656, 21521, 26123));
Данная запись означает, что элемент массива Data с индексом 8 содержит 11 повторов упакованных значений в кадре, а элементы 0,6,9 – имеют по 15 повторов в течении всего времени эксперименты.
Same – элементы этого динамического массива, представляют из себя два числа, первое – индекс массива Data, второе – количество повторов при поэлементном сравнении. Например, Data[0] – массив, который содержит 15 элементов. Повтор, это когда точно такая же реализация случится в процессе записи. Можно думать, что это редчайшее событие…
Size – поле индикатор уровня памяти. В данном случае равно 1. Это значит, что работа идет с одним кадром.
И так, данная структура заполняется не повторяющимися комбинациями. Происходит это при каждом нажатии кнопки Record. Я не могу себе представить, что это можно сделать априорно с рандомайзингом, так как комбинации значений сильно зависят от предустановленных параметров фильтров и различных уровней триггеров. И вполне возможно, что какие-то комбинации вообще не будет реализованы. Например, значения с высокими гармониками. И это есть априорное знание, характерное именно для речи, которое можно использовать для дальнейшего уменьшения массива и повышения быстродействия. Заметьте, что все шипящие звуки фактически «шипят» одинаково. Ну, по крайней мере, разнообразия в этом «шипе» не так уж и много.
Предварительные результаты эксперимента.
Вначале выставляем приемлемое значение всех уровней и фильтров. Субъективно. Затем нажимаем Record и произносим одно слово с разными интонациями и громкостью. Затем похожее по звучанию слово… При каждой записи в текстовом поле выводится информация:
- Массивов памяти: 45 - количество элементов массива Data;
- Массивов с повторами: 2 - количество абсолютно одинаковых массивов;
- Памяти: 1124 - размер массива Data в байтах;
- Повторы с длинами: ,13,12 - наиболее популярные длины массивов, которые повторяются;
После сотни нажатий и произнесений слов: маманя, деда, няня, мама, баба… ко мне постучали обеспокоенные домочадцы… После чашки кофе я посмотрел файл: mamanya_deda_baba.txt
Результату я удивился:
- Массивов памяти: 4012
- Массивов с повторами: 2058
- Памяти: 99170
- Повторы с длинами: ,13,14,14,15,12,15,15,12,8,11,13…
Что это значит?
- 50% повторов, и их число будет расти;
- 99 килобайт – это мелочь;
- Скорость приемлемая;
- Информативная длинна массива от 8 до 20;
Конечно, эти результаты предварительные. Но, есть ещё…
Порох в пороховницах.
В основе конечно лежит допущение, что в массиве 50 Х 256 точек есть вся необходимая и достаточная информация для распознавания. Этот массив, по моему мнению, получился не большим. Поэтому есть предположение, что на основе такой методики по заполнению динамического массива можно будет в дальнейшем перейти от классического распознавания к фактическому нахождению уже имеющихся накопленных данных без привлечения математических ухищрений.
Мысли вслух:
А кто сказал, что массивы разной длины нельзя сравнивать? Можно сделать оценку сравнения малого массива с соответствующей частью большого, тем более, что упакованные таким образом значения сами ранжируются на основе высоты гармоник, см. как выглядит массив Data.
Математические ухищрения все же полезны. Например, в данный момент оценивается абсолютное совпадение по всем элементам. А кто сказал, что нельзя применить к равномерным массивам корреляционную функцию, результат же оформить в том же классе TmemLevelSound.
Если минимальная задача стоит как распознавание фонем, то в дальнейшем необходимо обдумать как оформить следующий уровень с параметром Size = 2. Элементом массива Data в этом случае будут не реализации кадра с упакованными значениями, а индексы массива Data нижнего уровня.
Lmem_sound[1].Data[n][k]:= (0,1),(2,0)…(3,1); где
0 – соответствует массиву (1372, 2324, 3615, 4894, 5926, 7295, 8577, 9602, 10632, 11130, 13085, 16651, 20237, 22552, 26120);
1 – (271, 1409, 3863, 5162, 6480, 7467, 7986, 9177, 9853, 11338, 11796, 13077, 13843, 14860, 15632, 22027); см. пример массива Data.
Сравнения так же понятны, а сортировка будет аналогично тому, как фраза «мама мыла» опережает фразу «маша мыла».
И это еще не всё, продолжение следует...
Некоторые технические особенности.
Программа DFTV не адаптирована по быстродействию. Визуализация в реальном масштабе времени может тормозить компьютер. Если посмотреть на Рис. 1 в статусной строке внизу стоит цифра 2012. Это означает, что мой компьютер справляется. Если будет цифра больше 2500, могут быть проблемы. Запись длится 2000 мс, из-за вычислений спектра набегает еще.
Обзор:
| «Использование оконных функций в задачах цифрового спектрального анализа. Примеры и рекомендации». Отличная статья. |
| «Компьютерное распознавание и порождение речи» |
|
«Дискретное преобразование Фурье» Ба-хуссейн А.А. Именно здесь формула для вычисления коэффициентов представлена не через комплексную переменную, которая сжырает мозг и ресурсы компа, а через классический синус и косинус! Как и должно быть, ибо все эти мнимые числа для пущей учености введены, для соискания очень ученых степеней... И не надо мне говорить о том, что я не люблю математику. Пусть тот, кто знает что такое метод функции Грина напишет мне письмо. Физический смысл забывать нельзя. Все в Мире есть колебания, которые описываются тригонометрическими функциями, а прочие созданы только для удобства, как например преобразования Лапласа. Хау, я всё сказал... |
[1] https://www.google.com/intl/en/chrome/demos/speech.html - распознавание голоса в Google.
[2] http://www.speechpro.ru/ - Центр Речевых Технологий.
[3] http://www.keklab.ru/buf/ai/psychoacoustics.pdf - Ирина Алдошина «Основы психоакустики».
[4] http://websound.ru/articles/theory/fft.htm - «FFT анализ», Автор: Дмитрий Михайлов.
http://prosound.ixbt.com/education/spektr-analys.shtml - «Спектроанализатор – что мы на нем видим?» Алексей Лукин.
http://forum.sources.ru/index.php?showtopic=145994 – форум «Исходники.RU. Тема посвящена фонемному распознаванию речи.
[5] http://ru.wikipedia.org/wiki/%CA%EE%F0%F0%E5%EB%FF%F6%E8%FF – матерал Вики о корреляционной функции Пирсона.
[6] http://www.phviewer.ru/article/o-kepstralnom-analize-v-popularnoj-forme - очень хорошая статья "О кепстральном анализе в популярной форме"Суворов В.Н., "Ви Тэк", Санкт.Петербург, Россия. От себя добавлю, что не надо сжимать ZIP-ом JPG - файл.
[7] http://zhurnal.ape.relarn.ru/articles/2003/148.pdf - «Распознавание речевых сигналов на основе метода обеляющего фильтра» Бочаров И.В.( Этот e-mail адрес защищен от спам-ботов, для его просмотра у Вас должен быть включен Javascript ), Акатьев Д.Ю.
[8] http://security-corp.org/os/linux/2986-filtr-kalmana-vvedenie.html - «Фильтр Калмана — Введение». Только после этой статьи стало понятно, что это такое.
Обновлено (19.06.2013 07:09)