–†–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ —А–µ—З–Є –≤ —А–∞–Љ–Ї–∞—Е –њ—А–Њ–±–ї–µ–Љ—Л –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞.
 |
| 
–≤—Б–µ —А–∞–≤–љ–Њ, –Ј–і–Њ—А–Њ–≤–Њ –њ–Њ–ї—Г—З–∞—О—В—Б—П —Н—В–Є –њ—Г–Ј—Л—А–Є. –Р —З—В–Њ? –Ґ–∞–Ї –Є –љ–∞–Ј–Њ–≤—Г:
–њ—Г–Ј—Л—А–Є. –Э–µ—В, –љ–∞–≤–µ—А–љ–Њ–µ, –ї—Г—З—И–µ "–њ–Њ–ї–Њ—Б—В–Є". –Я–Њ–ї–Њ—Б—В–Є –Љ–∞–ї—П–љ–Њ–≤–∞.
"–Ь-–њ–Њ–ї–Њ—Б—В–Є". –У–Љ...¬ї
(–Р—А–Ї–∞–і–Є–є –Є –С–Њ—А–Є—Б –°—В—А—Г–≥–∞—Ж–Ї–Є–µ. –Ч–∞ –Љ–Є–ї–ї–Є–∞—А–і –ї–µ—В –і–Њ –Ї–Њ–љ—Ж–∞ —Б–≤–µ—В–∞.)
–Я—А–Є–Љ–µ—З–∞–љ–Є–µ.
–Ф–∞–љ–љ–∞—П —Б—В–∞—В—М—П –≤ –µ—С –љ–∞–і–ї–µ–ґ–∞—Й–µ–Љ –≤–Є–і–µ –±—Г–і–µ—В –њ–Њ—Б—В–µ–њ–µ–љ–љ–Њ –Њ—Д–Њ—А–Љ–ї—П—В—М—Б—П. –Я–Њ–Ї–∞ –ґ–µ –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М –≤ –љ–µ–є –њ–Њ—П–≤—П—В—Б—П –Љ–∞—В–µ—А–Є–∞–ї—Л, –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л–µ –і–ї—П –Њ–±—Б—Г–ґ–і–µ–љ–Є—П –і–∞–љ–љ–Њ–є —В–µ–Љ—Л –љ–∞ —Д–Њ—А—Г–Љ–µ Gotai.net.
–Я–Њ—Б—В–∞–љ–Њ–≤–Ї–∞ –Ј–∞–і–∞—З–Є.
–†–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ –≥–Њ–ї–Њ—Б–∞, –Ї–∞–Ї –Ј–∞–і–∞—З–∞ –і–ї—П –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П —А–µ—И–µ–љ–∞ –≤ –Њ—Б–љ–Њ–≤–љ–Њ–Љ –≤ –Ї–Њ–Љ–њ–∞–љ–Є–Є Google[1]. –І—В–Њ–±—Л —Г–≤–Є–і–µ—В—М –Ї–∞–Ї —Н—В–Њ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –љ–∞–і–Њ –Ј–∞–є—В–Є —Б –њ–Њ–Љ–Њ—Й—М—О –±—А–∞—Г–Ј–µ—А–∞ Chrome. –У–Њ–ї–Њ—Б–Њ–≤—Л–µ —Б–Њ–Њ–±—Й–µ–љ–Є—П —А–∞—Б–њ–Њ–Ј–љ–∞—О—В—Б—П –±–µ–Ј –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П. –Я–Њ–Љ–µ—Е–Њ–≤–∞—П –Њ–±—Б—В–∞–љ–Њ–≤–Ї–∞ –Є –Ї–∞—З–µ—Б—В–≤–Њ –Љ–Є–Ї—А–Њ—Д–Њ–љ–љ–Њ–є –Ј–∞–њ–Є—Б–Є –і–Њ–ї–ґ–љ—Л –њ—А–Є —Н—В–Њ–Љ –±—Л—В—М –љ–∞ —Е–Њ—А–Њ—И–µ–Љ —Г—А–Њ–≤–љ–µ. –Ч–∞–і–∞—З–∞ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П —Б–ї–Є—В–љ–Њ–є —А–µ—З–Є, –љ–∞ –Љ–Њ–є –≤–Ј–≥–ї—П–і, –њ–Њ–Ї–∞ –љ–µ –Є–Љ–µ–µ—В —В–∞–Ї–Є—Е –ґ–µ —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ –Є –≤—Л–њ–Њ–ї–љ—П–µ—В—Б—П —Б –њ—А–Є–Љ–µ–љ–µ–љ–Є–µ–Љ –Є–љ—В–µ—А–∞–Ї—В–Є–≤–љ—Л—Е –Љ–µ—В–Њ–і–Њ–≤[2].
–Т—Б–µ, —З—В–Њ –і–µ–ї–∞–µ—В—Б—П –љ–∞ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –≤ —Н—В–Њ–є –Њ–±–ї–∞—Б—В–Є —Г—Б–ї–Њ–≤–љ–Њ –љ–∞–Ј–Њ–≤–µ–Љ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є–Љ –њ–Њ–і—Е–Њ–і–Њ–Љ. –І—В–Њ —Н—В–Њ –Ј–љ–∞—З–Є—В? –Ч–∞–і–∞—З–∞ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В—Б—П –њ—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ –Ї–∞–Ї –Ј–∞–і–∞—З–∞ –њ–Њ—Б—В—А–Њ–µ–љ–Є—П –љ–µ–Ї–Њ–µ–≥–Њ —Д–Є–ї—М—В—А–∞. –Я—Г—Б—В—М –Њ–љ –±—Г–і–µ—В —Б–Ї–Њ–ї—М —Г–≥–Њ–і–љ–Њ —Б–ї–Њ–ґ–љ—Л–є, —Б –Њ–±—Г—З–µ–љ–Є–µ–Љ, —Б –њ–Њ–і–Ї–ї—О—З–µ–љ–Є–µ–Љ –∞–ї—Д–∞–≤–Є—В–∞, –љ–∞ –Њ—Б–љ–Њ–≤–µ –Ї–Њ—В–Њ—А–Њ–≥–Њ –і–µ–ї–∞–µ—В—Б—П —Д–Њ–љ–µ—В–Є—З–µ—Б–Ї–Њ–µ –њ—А–µ–і—Б–Ї–∞–Ј–∞–љ–Є–µ –Є —В.–і. –Т—Б–µ —Н—В–Њ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є–є –њ–Њ–і—Е–Њ–і.
–Ъ–∞–Ї –Љ–Њ–ґ–љ–Њ –њ–Њ—Б—В–∞–≤–Є—В—М –Ј–∞–і–∞—З—Г —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Є–љ–∞—З–µ? –Я—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ –Њ—В–Љ–µ—З—Г, —З—В–Њ –≤ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–Љ –њ–Њ–і—Е–Њ–і–µ –µ—Б—В—М –љ–µ–Ї–Є–є —Г—А–Њ–≤–µ–љ—М –Љ–∞—В–µ–Љ–∞—В–Є–Ј–∞—Ж–Є–Є: —Н—В–Њ –Є –§—Г—А—М–µ-–њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ, –Њ–Ї–Њ–љ–љ—Л–µ —Д–Є–ї—М—В—А—Л –Є —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П –њ—А–µ–і–Њ–±—А–∞–±–Њ—В–Ї–Є —Ж–Є—Д—А–Њ–≤—Л–Љ–Є —Д–Є–ї—М—В—А–∞–Љ–Є –Є –љ–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є –Є –Љ–љ–Њ–≥–Њ–µ –і—А—Г–≥–Њ–µ. –Ш –Љ–µ–љ—П –≤—Б–µ–≥–і–∞ —Г–і–Є–≤–ї—П–ї–∞ –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В—М —З–µ–ї–Њ–≤–µ–Ї–∞ —Б–ї—Л—И–∞—В—М –Є —Г–Ј–љ–∞–≤–∞—В—М –Ї—В–Ю –≥–Њ–≤–Њ—А–Є—В –Є —З—В–Ю –≥–Њ–≤–Њ—А–Є—В—Б—П. –Ш –њ—А–Є —Н—В–Њ–Љ —Б–Њ–≤–µ—А—И–µ–љ–љ–µ–є—И–∞—П —В–∞–є–љ–∞ –≤ —В–Њ–Љ, –≥–і–µ –Є –Ї–∞–Ї –њ–Њ–і–Њ–±–љ—Л–µ –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–µ –Љ–µ—В–Њ–і—Л —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ—Л? –Ш –µ—Б—В—М –ї–Є –Њ–љ–Є? –Ь–Њ–ґ–љ–Њ –ї–Є –љ–∞–є—В–Є —Б–њ–Њ—Б–Њ–± —А–µ–∞–ї–Є–Ј–Њ–≤–∞—В—М –Ї–Њ–Љ–њ—М—О—В–µ—А–љ—Г—О –Љ–Њ–і–µ–ї—М —В–∞–Ї, —З—В–Њ–±—Л –≤ –њ—А–Њ—Ж–µ—Б—Б–µ –Њ–±—Г—З–µ–љ–Є—П –≤—Б–µ –љ–µ–Њ–±—Е–Њ–і–Є–Љ—Л–µ —Б–њ–Њ—Б–Њ–±—Л —Д–Є–ї—М—В—А–∞—Ж–Є–Є –Є —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П —А–µ—З–µ–≤–Њ–≥–Њ –њ–Њ—В–Њ–Ї–∞ –≤—Л—Б—В—А–∞–Є–≤–∞–ї–Є—Б—М –±—Л –њ–Њ—Б—В–µ–њ–µ–љ–љ–Њ, –∞ –љ–µ –Ј–∞–Ї–ї–∞–і—Л–≤–∞–ї–Є—Б—М –±—Л –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В–Њ–Љ –Ј–∞—А–∞–љ–µ–µ. –Ъ–Њ–љ–µ—З–љ–Њ –ґ–µ —З—В–Њ вАУ —В–Њ –і–Њ–ї–ґ–љ–Њ –±—Л—В—М –Ј–∞–ї–Њ–ґ–µ–љ–Њ –∞–њ—А–Є–Њ—А–љ–Њ. –Э–∞–њ—А–Є–Љ–µ—А, —З–∞—Б—В–Њ—В–љ–Њ–µ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ –≤ —Г—Е–µ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –Є —Н—В–Њ –Њ–њ–Є—Б–∞–љ–Њ –≤ –Ј–∞–Љ–µ—З–∞—В–µ–ї—М–љ–Њ–є –Ї–љ–Є–≥–µ –Ш—А–Є–љ—Л –Р–ї–і–Њ—И–Є–љ–Њ–є ¬Ђ–Ю—Б–љ–Њ–≤—Л –њ—Б–Є—Е–Њ–∞–Ї—Г—Б—В–Є–Ї–Є[3]¬ї
–Ф–ї—П —В–Њ–≥–Њ —З—В–Њ–±—Л –њ—А–Є–±–ї–Є–Ј–Є—В—М—Б—П –Ї –њ–Њ–љ–Є–Љ–∞–љ–Є—О —В–Њ–≥–Њ, –Љ–Њ–ґ–љ–Њ –ї–Є –њ–Њ–і–Њ–±–љ—Г—О –Ј–∞–і–∞—З—Г —А–µ–∞–ї–Є–Ј–Њ–≤–∞—В—М –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –≤–љ–Є–Љ–∞—В–µ–ї—М–љ–Њ –Є–Ј—Г—З–Є—В—М –≥–Њ–ї–Њ—Б–Њ–≤–Њ–є –њ–Њ—В–Њ–Ї, –Є –њ–Њ–љ—П—В—М –љ–∞ –Ї–∞–Ї–Є–µ —Б–Њ—Б—В–∞–≤–ї—П—О—Й–Є–µ —Н–ї–µ–Љ–µ–љ—В—Л –µ–≥–Њ —А–∞–Ј–ї–Њ–ґ–Є—В—М. –Ь–љ–µ –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В—Б—П, —З—В–Њ –Є–Љ–µ–љ–љ–Њ —Б–Њ —Б–њ–µ–Ї—В—А–Њ–Љ, –∞ –љ–µ —Б –∞–Љ–њ–ї–Є—В—Г–і–љ–Њ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–µ–є –Р–¶–Я –љ–∞–і–Њ –Є–Љ–µ—В—М –і–µ–ї–Њ. –Ю–± —Н—В–Њ–Љ –њ–Є—И—Г—В –Љ–љ–Њ–≥–Є–µ[4].
–Ш–љ—Б—В—А—Г–Љ–µ–љ—В–∞—А–Є–є –і–ї—П –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є—П.
–Ф–ї—П –Є–Ј—Г—З–µ–љ–Є—П —А–µ—З–µ–≤–Њ–≥–Њ –њ–Њ—В–Њ–Ї–∞ –њ—А–µ–і–ї–∞–≥–∞–µ—В—Б—П –њ—А–Њ–≥—А–∞–Љ–Љ–∞ DFTV, –љ–∞–њ–Є—Б–∞–љ–љ–∞—П –љ–∞ Delphi7 –±–µ–Ј –њ—А–Є–≤–ї–µ—З–µ–љ–Є—П —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л—Е –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В–Њ–≤. –Я—А–Њ–≥—А–∞–Љ–Љ–∞ –љ–µ –і–ї—П –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П, —Б –Є—Б—Е–Њ–і–љ–Є–Ї–∞–Љ–Є, –њ–Њ—Н—В–Њ–Љ—Г –≤—Б–µ –Њ—И–Є–±–Ї–Є –Є –љ–µ —А–∞–Ј–≤–Є—В—Л–є –Є–љ—В–µ—А—Д–µ–є—Б –њ—А–Є–і–µ—В—Б—П –њ—А–Є–љ—П—В—М –Ї–∞–Ї –µ—Б—В—М.
–Т–љ–∞—З–∞–ї–µ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –Њ–њ–Є—Б–∞—В—М –Ї–∞–Ї–Њ–µ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В —Б–Њ –Ј–≤—Г–Ї–Њ–Љ –Є —Б —З–µ–Љ –≤ –Є—В–Њ–≥–µ —А–∞–±–Њ—В–∞–µ—В –њ—А–Њ–≥—А–∞–Љ–Љ–∞.
- –І–∞—Б—В–Њ—В–∞ –і–Є—Б–Ї—А–µ—В–Є–Ј–∞—Ж–Є–Є(Hz): 16000;
- –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ј–љ–∞—З–µ–љ–Є–є –≤ –Ї–∞–і—А–µ: 640;
- –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –≥–∞—А–Љ–Њ–љ–Є–Ї: 256/(6375Hz);
- –†–∞–Ј—А–µ—И–µ–љ–Є–µ –њ–Њ –≥–∞—А–Љ–Њ–љ–Є–Ї–∞–Љ: 25(Hz);
- –†–∞–Ј—А—П–і–љ–Њ—Б—В—М –Р–¶–Я 16 –±–Є—В;
- –Р–Љ–њ–ї–Є—В—Г–і–љ–∞—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П –Ј–≤—Г–Ї–∞ (-32768..32767) —В–Є–њ smallint;
- –Т—А–µ–Љ—П –Ј–∞–њ–Є—Б–Є(ms): 2000;
- –Ф–ї–Є—В–µ–ї—М–љ–Њ—Б—В—М –Ї–∞–і—А–∞(ms): 40;
- –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ї–∞–і—А–Њ–≤: 50;
–Т –Ї–∞–ґ–і–Њ–Љ –Ї–∞–і—А–µ —А–µ–∞–ї–Є–Ј—Г–µ—В—Б—П —Д—Г–љ–Ї—Ж–Є—П –∞–Љ–њ–ї–Є—В—Г–і —Б–њ–µ–Ї—В—А–∞. –Т—Б–µ–≥–Њ –≤ –Є—В–Њ–≥–µ –њ–Њ–ї—Г—З–∞–µ—В—Б—П –Љ–∞—Б—Б–Є–≤ —Б —А–∞–Ј–Љ–µ—А–љ–Њ—Б—В—М—О 50 –• 256 –Ј–љ–∞—З–µ–љ–Є–є. –Ъ–∞–ґ–і–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ —В–Є–њ–∞ byte (0..255).
–Х—Б–ї–Є –њ–Њ–і–Ї–ї—О—З–µ–љ –Љ–Є–Ї—А–Њ—Д–Њ–љ, —В–Њ –њ—А–Є –Ј–∞–њ—Г—Б–Ї–µ –њ—А–Њ–≥—А–∞–Љ–Љ—Л –њ–Њ—П–≤–Є—В—Б—П –∞–Љ–њ–ї–Є—В—Г–і–љ–∞—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П –Є —Б–њ–µ–Ї—В—А–∞–ї—М–љ–∞—П. –£—А–Њ–≤–µ–љ—М –Љ–Є–Ї—А–Њ—Д–Њ–љ–∞ –≤ –њ—А–Њ–≥—А–∞–Љ–Љ–µ –љ–µ —А–µ–≥—Г–ї–Є—А—Г–µ—В—Б—П, —Н—В–Њ –љ–∞–і–Њ –і–µ–ї–∞—В—М —Б—А–µ–і—Б—В–≤–∞–Љ–Є –Њ–њ–µ—А–∞—Ж–Є–Њ–љ–љ–Њ–є —Б–Є—Б—В–µ–Љ—Л. –Ь–Њ–ґ–љ–Њ —В–∞–Ї –ґ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —И—Г–Љ–Њ–њ–Њ–і–∞–≤–ї–µ–љ–Є–µ, —Г—Б—В—А–∞–љ–µ–љ–Є–µ —А–µ–≤–µ—А–±–µ—А–∞—Ж–Є–Є –Є –њ—А–Њ—З–Є–µ —Д—Г–љ–Ї—Ж–Є–Є, –µ—Б–ї–Є —В–∞–Ї–Њ–≤—Л–µ –Є–Љ–µ—О—В—Б—П –љ–∞ –Ј–≤—Г–Ї–Њ–≤–Њ–є –Ї–∞—А—В–µ.
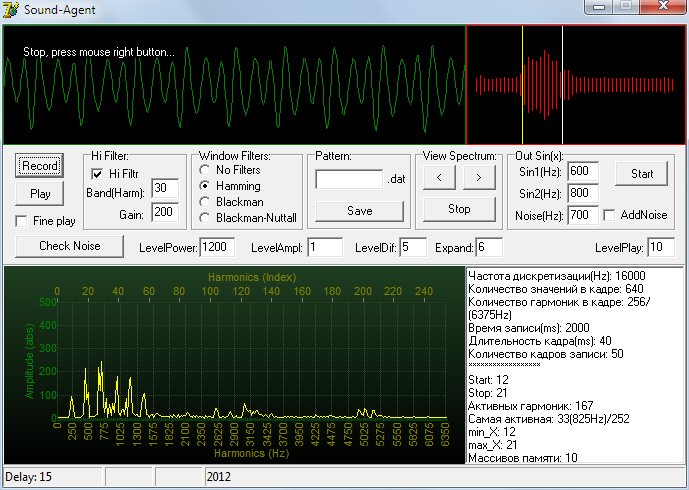
–†–Є—Б. 1
–Т–љ–∞—З–∞–ї–µ –љ–∞–і–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М —Г—А–Њ–≤–µ–љ—М —И—Г–Љ–∞ –Ї–љ–Њ–њ–Ї–Њ–є Check Noise. –°–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–µ–µ –∞–±—Б—В—А–∞–Ї—В–љ–Њ–µ —З–Є—Б–ї–Њ –њ–Њ—П–≤–Є—В—Б—П –≤ –њ–Њ–ї–µ LevelPower. –Х–≥–Њ —В–∞–Ї –ґ–µ –Љ–Њ–ґ–љ–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М –≤—А—Г—З–љ—Г—О. –Х—Б–ї–Є –≤—Л –њ—А–Њ–Є–Ј–љ–Њ—Б–Є—В–µ —Д—А–∞–Ј—Г –Є –Њ–љ–∞ –Њ—В–Њ–±—А–∞–ґ–∞–µ—В—Б—П –≤ –≤–µ—А—Е–љ–µ–Љ –≥—А–∞—Д–Є–Ї–µ, —В–Њ –Љ–Њ–ґ–љ–Њ –љ–∞–ґ–∞—В—М –Ї–љ–Њ–њ–Ї—Г Record. –Ч–∞–њ–Є—Б—М –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П –≤ —В–µ—З–µ–љ–Є–Є 2 —Б–µ–Ї—Г–љ–і. –Т –њ—А–∞–≤–Њ–Љ –≤–µ—А—Е–љ–µ–Љ —Г–≥–ї—Г –њ–Њ—П–≤–Є—В—Б—П –Њ–≥–Є–±–∞—О—Й–∞—П —Б–Є–≥–љ–∞–ї–∞, –Ї–Њ—В–Њ—А–∞—П –љ–∞ –Њ—Б–љ–Њ–≤–µ —Г—А–Њ–≤–љ—П —И—Г–Љ–∞ –±—Г–і–µ—В –≤—Л–і–µ–ї–µ–љ–∞ –≤–µ—А—В–Є–Ї–∞–ї—М–љ—Л–Љ–Є –ї–Є–љ–Є—П–Љ–Є. –≠—В–Є—Е –ї–Є–љ–Є–є –Љ–Њ–ґ–µ—В –±—Л—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤—Г —Е–∞—А–∞–Ї—В–µ—А–љ—Л—Е —Д–Њ–љ–µ–Љ–љ—Л—Е —Д—А–∞–≥–Љ–µ–љ—В–Њ–≤. –Т –њ—А–∞–≤–Њ–Љ –љ–Є–ґ–љ–µ–Љ —Г–≥–ї—Г –≤ —В–µ–Ї—Б—В–Њ–≤–Њ–Љ –Њ–Ї–љ–µ –њ–Њ—П–≤—П—В—Б—П –љ–µ–Ї–Њ—В–Њ—А—Л–µ —Е–∞—А–∞–Ї—В–µ—А–Є—Б—В–Є–Ї–Є.
–У—А–∞—Д–Є–Ї –≥–∞—А–Љ–Њ–љ–Є–Ї –Љ–Њ–ґ–љ–Њ –Љ–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞—В—М –њ–Њ X –Є –њ–Њ Y. –≠—В–Њ –Њ–±—Л—З–љ—Л–є –Ї–Њ–Љ–њ–Њ–љ–µ–љ—В Chart. –Ъ—В–Њ –љ–µ –Ј–љ–∞–Ї–Њ–Љ, —Б–Ї–∞–ґ—Г, —З—В–Њ –Љ–Њ–ґ–љ–Њ –≤—Л–і–µ–ї—П—В—М –Њ–±–ї–∞—Б—В—М –љ–∞ —Н—В–Њ–Љ –≥—А–∞—Д–Є–Ї–µ –Љ—Л—И–Ї–Њ–є —Б –љ–∞–ґ–∞—В–Њ–є –ї–µ–≤–Њ–є –Ї–љ–Њ–њ–Ї–Њ–є, –і–µ–ї–∞—П –і–≤–Є–ґ–µ–љ–Є–µ —Б –ї–µ–≤–Њ–≥–Њ –≤–µ—А—Е–љ–µ–≥–Њ —Г–≥–ї–∞ –≤ –њ—А–∞–≤—Л–є –љ–Є–ґ–љ–Є–є. –Т–Њ–Ј–≤—А–∞—В –≤ –Є—Б—Е–Њ–і–љ—Л–є –Љ–∞—Б—И—В–∞–± –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В—Б—П –Њ–±—А–∞—В–љ—Л–Љ –і–≤–Є–ґ–µ–љ–Є–µ–Љ. –£–і–µ—А–ґ–Є–≤–∞—П –љ–∞–ґ–∞—В–Њ–є –њ—А–∞–≤—Г—О –Ї–Њ–њ–Ї—Г –Љ—Л—И–Є –Љ–Њ–ґ–љ–Њ —Б–і–≤–Є–≥–∞—В—М –Ї–∞—А—В–Є–љ–Ї—Г –≤–Њ –≤—Б–µ —Б—В–Њ—А–Њ–љ—Л.
–°–µ–Ї—Ж–Є—П View Spectrum –њ–Њ–Ј–≤–Њ–ї—П–µ—В –њ–Њ–Ї–∞–і—А–Њ–≤–Њ —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞—В—М —А–µ–∞–ї–Є–Ј–∞—Ж–Є—О –≥–∞—А–Љ–Њ–љ–Є–Ї. –Т—Б–µ–≥–Њ –Ї–∞–і—А–Њ–≤ 50. –Я—А–Є —Н—В–Њ–Љ –±—Г–і—Г—В –њ–Њ–Ї–∞–Ј–∞–љ—Л –ї–Њ–Ї–∞–ї—М–љ—Л–µ –Љ–∞–Ї—Б–Є–Љ—Г–Љ—Л —Б–њ–µ–Ї—В—А–∞–ї—М–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ –±—Г–і—Г—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –і–ї—П –≤—Л–≤–Њ–і–∞ —Б–Є–≥–љ–∞–ї–∞ –≤ —А–µ–ґ–Є–Љ–µ Play. –Ъ–љ–Њ–њ–Ї–∞ Stop –≤ —Н—В–Њ–є —Б–µ–Ї—Ж–Є–Є –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В –њ—А–Њ–≥—А–∞–Љ–Љ—Г –≤ –Њ–±—Л—З–љ—Л–є —А–µ–ґ–Є–Љ.
–Ъ–љ–Њ–њ–Ї–∞ Play –њ—А–Њ–Є–≥—А—Л–≤–∞–µ—В –≤–µ—Б—М –Љ–∞—Б—Б–Є–≤ –і–∞–љ–љ—Л—Е. –Ю –љ–µ–Љ –±—Г–і–µ—В —Б–Ї–∞–Ј–∞–љ–Њ –њ–Њ–Ј–ґ–µ. –У–∞–ї–Њ—З–Ї–∞ Fine Play –њ–Њ–Ј–≤–Њ–ї–Є—В –Њ—В—Б–µ—З—М —В–µ –Њ–±–ї–∞—Б—В–Є –Њ–≥–Є–±–∞—О—Й–µ–є, –Ї–Њ—В–Њ—А—Л–µ –љ–Є–ґ–µ —И—Г–Љ–Њ–≤–Њ–≥–Њ –њ–Њ—А–Њ–≥–∞, —Н—В–Њ –∞–Ї—В—Г–∞–ї—М–љ–Њ —В–Њ–ї—М–Ї–Њ –њ—А–Є –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є–Є.
–Я–Њ–ї–µ LevelPLay - –≥—А–Њ–Љ–Ї–Њ—Б—В—М –њ—А–Є –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є–Є.
–Т—Б–µ —Г—А–Њ–≤–љ–Є –Є–Љ–µ—О—В –Њ—В–љ–Њ—И–µ–љ–Є–µ –љ–µ –Ї –∞–Љ–њ–ї–Є—В—Г–і–љ–Њ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –њ–Њ—Б–ї–µ –Р–¶–Я, –∞ –Ї —Б–њ–µ–Ї—В—А–∞–ї—М–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є:
Level Ampl вАУ —Г—А–Њ–≤–µ–љ—М, –љ–Є–ґ–µ –Ї–Њ—В–Њ—А–Њ–≥–Њ –≥–∞—А–Љ–Њ–љ–Є–Ї–∞ –љ–µ –Ј–∞–њ–Є—Б—Л–≤–∞–µ—В—Б—П.
LevelDif- —Г—А–Њ–≤–µ–љ—М –њ–µ—А–≤–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–љ–Њ–є, –≤—Л—И–µ –Ї–Њ—В–Њ—А–Њ–≥–Њ —Г—З–Є—В—Л–≤–∞–µ—В—Б—П –ї–Њ–Ї–∞–ї—М–љ—Л–є –Љ–∞–Ї—Б–Є–Љ—Г–Љ.
Expand вАУ –љ–µ–Ї–Є–є —Г—А–Њ–≤–µ–љ—М, –Ї–Њ—В–Њ—А—Л–є –Њ–њ—А–µ–і–µ–ї—П–µ—В –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є–є –і–Є–∞–њ–∞–Ј–Њ–љ, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –≤—Л—З–Є—Б–ї—П—О—В—Б—П –∞–Љ–њ–ї–Є—В—Г–і—Л –≥–∞—А–Љ–Њ–љ–Є–Ї. –Ь–∞–ї–Њ–µ –µ–≥–Њ —З–Є—Б–ї–Њ–≤–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –≤–Ї–ї—О—З–∞–µ—В —И—Г–Љ—Л, –±–Њ–ї—М—И–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –Њ—В—Б–µ–Ї–∞–µ—В —И—Г–Љ—Л.
–°–µ–Ї—Ж–Є—П Hi Filter вАУ –≤–Ї–ї—О—З–∞–µ—В —Д–Є–ї—М—В—А –≤–µ—А—Е–љ–Є—Е —З–∞—Б—В–Њ—В, –њ–Њ–ї–Њ—Б–∞ —Б—А–µ–Ј–∞ –Њ–њ—А–µ–і–µ–ї—П–µ—В—Б—П –њ–Њ–ї–µ–Љ Band(Harm) –≤ –≥–∞—А–Љ–Њ–љ–Є–Ї–∞—Е, —Г—Б–Є–ї–µ–љ–Є–µ –≤ –њ–Њ–ї–Њ—Б–µ –Њ–њ—А–µ–і–µ–ї—П–µ—В—Б—П –њ–Њ–ї–µ–Љ Gain.
–Х—Б–ї–Є –љ–µ –≤–і–∞–≤–∞—В—М—Б—П –≤ –Њ–њ–Є—Б–∞–љ–љ—Л–µ –≤—Л—И–µ –њ–Њ–і—А–Њ–±–љ–Њ—Б—В–Є —Н—В–Є—Е –њ–∞—А–∞–Љ–µ—В—А–Њ–≤, —В–Њ –Љ–Њ–ґ–љ–Њ —Б–Ї–∞–Ј–∞—В—М, —З—В–Њ –Љ–∞–љ–Є–њ—Г–ї–Є—А—Г—П —В–Њ–ї—М–Ї–Њ LevelDif, Expand –Є Hi Filtr –Љ–Њ–ґ–љ–Њ –њ–Њ–і–Њ–±—А–∞—В—М –і–ї—П —А–∞–Ј–љ—Л—Е –Љ–Є–Ї—А–Њ—Д–Њ–љ–Њ–≤ –њ—А–Є–µ–Љ–ї–µ–Љ–Њ–µ –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є–µ –≥–Њ–ї–Њ—Б–Њ–≤–Њ–≥–Њ —Б–Њ–Њ–±—Й–µ–љ–Є—П.
–°–µ–Ї—Ж–Є—П Filters for Record –њ–Њ–Ј–≤–Њ–ї—П–µ—В –Њ—Ж–µ–љ–Є—В—М —А–∞–±–Њ—В—Г –Њ–Ї–Њ–љ–љ—Л—Е —Д–Є–ї—М—В—А–Њ–≤.
–°–µ–Ї—Ж–Є—П Out Sin(x) вАУ –≤–Ї–ї—О—З–∞–µ—В –≥–∞—А–Љ–Њ–љ–Є—З–µ—Б–Ї–Є–µ —Б–Є–≥–љ–∞–ї—Л –Є —И—Г–Љ –≤–Њ –≤—А–µ–Љ—П –Ј–∞–њ–Є—Б–Є.

–Ы–µ–≤–Њ–µ –Њ–Ї–љ–Њ вАУ —В–µ–Ї—Г—Й–∞—П –≥–Њ–ї–Њ—Б–Њ–≤–∞—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П, –њ—А–∞–≤–Њ–µ вАУ –њ–∞—В—В–µ—А–љ, –Ї–Њ—В–Њ—А—Л–є –Љ–Њ–ґ–љ–Њ –≤—Л–Ј–≤–∞—В—М —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–µ–є –Ї–Њ–Љ–∞–љ–і–Њ–є –§–∞–є–ї + –Ч–∞–≥—А—Г–Ј–Є—В—М –Њ–±—А–∞–Ј–µ—Ж –Є–Ј —Д–∞–є–ї–∞.
S—Бale Y –Љ–∞—Б—И—В–∞–±.
–Я–Њ –Њ—Б–Є X вАУ –љ–Њ–Љ–µ—А–∞ –Ї–∞–і—А–Њ–≤.
–Я–Њ –Њ—Б–Є Y вАУ –љ–Њ–Љ–µ—А–∞ –≥–∞—А–Љ–Њ–љ–Є–Ї –Є —З–∞—Б—В–Њ—В—Л.
Max View вАУ –µ—Б–ї–Є –≤—Л–±—А–∞–љ —Н—В–Њ—В –њ–∞—А–∞–Љ–µ—В—А, —В–Њ –Љ–Њ–ґ–љ–Њ —Г–≤–Є–і–µ—В—М –Ї–∞–Ї —А–∞—Б–њ—А–µ–і–µ–ї—П—О—В—Б—П –ї–Њ–Ї–∞–ї—М–љ—Л–µ –Љ–∞–Ї—Б–Є–Љ—Г–Љ—Л —Б–њ–µ–Ї—В—А–∞–ї—М–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є –≤ –Ї–∞–ґ–і–Њ–Љ –Ї–∞–і—А–µ.
Binarization вАУ —А–µ–ґ–Є–Љ –Њ—В–Њ–±—А–∞–ґ–µ–љ–Є—П –≤ –±–Є–љ–∞—А–љ–Њ–Љ –≤–Є–і–µ. –Т—Л—Б—В–∞–≤–ї—П–µ—В—Б—П —Г—А–Њ–≤–µ–љ—М –Є –љ–∞–ґ–Є–Љ–∞–µ—В—Б—П Apply.
Compare вАУ –њ—А–Њ—Б—В–Њ–µ —Б—А–∞–≤–љ–µ–љ–Є–µ –і–≤—Г—Е –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є, –≥–і–µ —Б–Њ–≤–њ–∞–і–µ–љ–Є—П –Є–љ–і–Є—Ж–Є—А—Г—О—В—Б—П. –°–Њ–≤–µ—А—И–µ–љ–љ–Њ –љ–µ –Є–љ—Д–Њ—А–Љ–∞—В–Є–≤–љ–Њ.
Correlation вАУ –њ–Њ–Ї–∞–і—А–Њ–≤–∞—П –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ–∞—П –Њ—Ж–µ–љ–Ї–∞ –≤ –њ—А–Њ—Ж–µ–љ—В–∞—Е –њ–Њ –Љ–µ—В–Њ–і—Г –Я–Є—А—Б–Њ–љ–∞[5].
–Ю—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В—Б—П –љ–µ –њ–Њ –≤—Б–µ–Љ—Г –Љ–∞—Б—Б–Є–≤—Г, –∞ –љ–∞ –Њ—Б–љ–Њ–≤–µ –≤—Л–і–µ–ї–µ–љ–љ–Њ–є –Њ–≥–Є–±–∞—О—Й–µ–є. –Ш–Љ–µ–љ–љ–Њ –њ–Њ—Н—В–Њ–Љ—Г –≤–∞–ґ–љ–Њ, —З—В–Њ–±—Л —Г—А–Њ–≤–µ–љ—М —И—Г–Љ–∞ LevelPower –±—Л–ї –≤—Л–±—А–∞–љ —В–∞–Ї, —З—В–Њ–±—Л –≤—Б—П —Д—А–∞–Ј–∞ –Њ—Ж–µ–љ–Є–≤–∞–ї–∞—Б—М –±—Л –Љ–Є–љ–Є–Љ–∞–ї—М–љ—Л–Љ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ–Љ –ї–Є–љ–Є–є, –Ї–∞–Ї —Н—В–Њ –њ–Њ–Ї–∞–Ј–∞–љ–Њ –љ–∞ –Њ–≥–Є–±–∞—О—Й–µ–є –љ–∞ –†–Є—Б1.
–І—В–Њ –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В –Є–Ј —Б–µ–±—П –Љ–∞—Б—Б–Є–≤ —Ж–Є—Д—А –њ–Њ—Б–ї–µ –љ–∞–ґ–∞—В–Є—П –Ї–љ–Њ–њ–Ї–Є Correlation?
–Э–∞ –Њ—Б–љ–Њ–≤–µ –∞–љ–∞–ї–Є–Ј–∞ –Њ–≥–Є–±–∞—О—Й–µ–є –Є —Г—А–Њ–≤–љ—П LevelPower –µ—Б—В—М –љ–∞—З–∞–ї—М–љ—Л–є –Ї–∞–і—А —Г –і–∞–љ–љ—Л—Е –≤ –ї–µ–≤–Њ–Љ –Њ–Ї–љ–µ –Є –љ–∞—З–∞–ї—М–љ—Л–є –Ї–∞–і—А –≤ –њ–∞—В—В–µ—А–љ–µ. –Э–∞ –†–Є—Б.1 –≤ —В–µ–Ї—Б—В–Њ–≤–Њ–Љ –Њ–Ї–љ–µ —Н—В–Є –і–≤–∞ —Б–Њ–±—Л—В–Є—П –Њ–±–Њ–Ј–љ–∞—З–µ–љ—Л –Ї–∞–Ї Start:12 –Є Stop: 21. –Ъ–∞–і—А вДЦ12 —В–µ–Ї—Г—Й–µ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –Є –љ–∞—З–∞–ї—М–љ—Л–є –Ї–∞–і—А –њ–∞—В—В–µ—А–љ–∞ –∞–љ–∞–ї–Є–Ј–Є—А—Г—О—В—Б—П –Є –≤ —А–µ–Ј—Г–ї—М—В–∞—В–µ –њ–Њ–ї—Г—З–∞–µ—В—Б—П –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В –Ї–Њ—А—А–µ–ї—П—Ж–Є–Є –≤ –њ—А–Њ—Ж–µ–љ—В–∞—Е. –≠—В–Њ —Б–∞–Љ–Њ–µ –њ–µ—А–≤–Њ–µ —З–Є—Б–ї–Њ –≤ —Б—В—А–Њ–Ї–µ вДЦ1. –Ъ–Њ–ї–Є—З–µ—Б—В–≤–Њ —Ж–Є—Д—А –≤ —Б—В—А–Њ–Ї–µ —А–∞–≤–љ–Њ –Ї–Њ–ї–Є—З–µ—Б—В–≤—Г –Ї–∞–і—А–Њ–≤ —В–µ–Ї—Г—Й–µ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є. –Я–Њ—Б–ї–µ–і–љ—П—П —Ж–Є—Д—А–∞ –≤ —Б—В—А–Њ–Ї–µ - –Є—Е —Б—А–µ–і–љ–µ–µ –Ј–љ–∞—З–µ–љ–Є–µ.
–Х—Б–ї–Є –≤–Љ–µ—Б—В–Њ –Ј–љ–∞—З–µ–љ–Є–є –≥–∞—А–Љ–Њ–љ–Є–Ї –≤–Ј—П—В—М —А–∞–Ј–љ–Є—Ж—Г –Љ–µ–ґ–і—Г –≥–∞—А–Љ–Њ–љ–Є–Ї–∞–Љ–Є –≤ —Б–Њ—Б–µ–і–љ–Є—Е –Ї–∞–і—А–∞—Е –Є –њ—А–Њ–≤–µ—Б—В–Є —В–µ –ґ–µ –Њ–њ–µ—А–∞—Ж–Є–Є, —В–Њ –њ–Њ–ї—Г—З–Є—В—Б—П –µ—Й–µ —В—А–Є —Б—В—А–Њ–Ї–Є:
- –°—В—А–Њ–Ї–∞ вДЦ2 DataUp[n][k]:=Data[n][k] - Data[n-1][k+1];
- –°—В—А–Њ–Ї–∞ вДЦ3 DataRight[n][k]:=Data[n][k] - Data[n-1][k];
- –°—В—А–Њ–Ї–∞ вДЦ4 DataDown[n][k]:=Data[n][k] - Data[n-1][k-1];
–У–і–µ n-–Ї–∞–і—А, k- –≥–∞—А–Љ–Њ–љ–Є–Ї–∞, Data[n][k] вАУ –Љ–∞—Б—Б–Є–≤ –∞–Љ–њ–ї–Є—В—Г–і –≥–∞—А–Љ–Њ–љ–Є–Ї.
–Ш —В–∞–Ї. –Ф–ї—П –Њ—Ж–µ–љ–Ї–Є –њ–Њ—Е–Њ–ґ–µ—Б—В–Є —В–µ–Ї—Г—Й–µ–≥–Њ —Б–ї–Њ–≤–∞ —Б –њ–∞—В—В–µ—А–љ–Њ–Љ, –Ј–∞–њ–Є—Б–∞–љ–љ—Л–Љ –Ј–∞—А–∞–љ–µ–µ, –љ—Г–ґ–љ–Њ –±—А–∞—В—М –≤–Њ –≤–љ–Є–Љ–∞–љ–Є–µ —Б—А–µ–і–љ–µ–µ –Ј–љ–∞—З–µ–љ–Є–µ –≤ –њ–µ—А–≤–Њ–є —Б—В—А–Њ–Ї–µ. –•–Њ—А–Њ—И–Є–Љ —Б–Њ–≤–њ–∞–і–µ–љ–Є–µ–Љ –Љ–Њ–ґ–љ–Њ —Б—З–Є—В–∞—В—М –Ј–љ–∞—З–µ–љ–Є–µ –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–∞ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Є –±–Њ–ї—М—И–µ 50%. –Ч–∞–њ–Є—Б—М –њ–∞—В—В–µ—А–љ–∞ –Є –њ–Њ—Б–ї–µ–і—Г—О—Й–∞—П –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ–∞—П –Њ—Ж–µ–љ–Ї–∞ –і–Њ–ї–ґ–љ–∞ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В—М –њ—А–Є –Њ–і–Є–љ–∞–Ї–Њ–≤—Л—Е —Г—А–Њ–≤–љ—П—Е, –Є—Е –Ј–љ–∞—З–µ–љ–Є—П —Б–Є–ї—М–љ–Њ –≤–ї–Є—П—О—В –љ–∞ —А–µ–Ј—Г–ї—М—В–∞—В. –Я—А–µ–ґ–і–µ, —З–µ–Љ –Ј–∞–њ–Є—Б—Л–≤–∞—В—М –њ–∞—В—В–µ—А–љ—Л, –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –љ–∞–є—В–Є –њ—А–Є–µ–Љ–ї–µ–Љ–Њ–µ —Б–Њ–Њ—В–љ–Њ—И–µ–љ–Є–µ —Г—А–Њ–≤–љ–µ–є. –Ъ—А–Є—В–µ—А–Є–µ–Љ –і–ї—П —Н—В–Њ–≥–Њ –Љ–Њ–ґ–µ—В —Б–ї—Г–ґ–Є—В—М —Б—Г–±—К–µ–Ї—В–Є–≤–љ–∞—П –Њ—Ж–µ–љ–Ї–∞ –Ј–≤—Г—З–∞–љ–Є—П, –±–µ–Ј —Б–Є–ї—М–љ—Л—Е –њ–Њ–Љ–µ—Е.
–Т—Л–≤–Њ–і—Л.
- –°–∞–Љ—Л–є –Є–љ—В–µ—А–µ—Б–љ—Л–є —А–µ–Ј—Г–ї—М—В–∞—В –і–ї—П –Љ–µ–љ—П —Н—В–Њ —В–Њ, —З—В–Њ –Љ–∞—Б—Б–Є–≤ –і–∞–љ–љ—Л—Е 50X256 —В–Њ—З–µ–Ї –њ—А–Є –Њ–±—А–∞—В–љ–Њ–Љ –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є–Є –Њ–±—А–∞–Ј—Г–µ—В –Ј–≤—Г—З–∞–љ–Є–µ, –Ї–Њ—В–Њ—А–Њ–µ —А–∞—Б–њ–Њ–Ј–љ–∞–µ—В—Б—П —З–µ–ї–Њ–≤–µ–Ї–Њ–Љ. –†–∞—Б–њ–Њ–Ј–љ–∞–µ—В—Б—П –Ї—В–Ю –Є —З—В–Ю –≥–Њ–≤–Њ—А–Є—В. –Э–∞–і–Њ –і–Њ–њ–Њ–ї–љ–Є—В—М, —З—В–Њ –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ –љ–µ –≤—Б–µ 256 –≥–∞—А–Љ–Њ–љ–Є–Ї –Є–љ—Д–Њ—А–Љ–∞—В–Є–≤–љ—Л, –њ–Њ—Н—В–Њ–Љ—Г –Љ–∞—Б—Б–Є–≤ –Є–Ј–±—Л—В–Њ—З–µ–љ –њ–Њ –≤–µ—А—В–Є–Ї–∞–ї–µ. –Ф–∞, –Є –њ–Њ –≥–Њ—А–Є–Ј–Њ–љ—В–∞–ї–Є —Б—А–µ–і–љ–µ–µ —Б–ї–Њ–≤–Њ –Љ–µ–љ—М—И–µ 2 —Б–µ–Ї—Г–љ–і. –Ь–∞—Б—Б–Є–≤ –њ—А–Є –Њ–±—А–∞—В–љ–Њ–Љ –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є–Є —Д–Њ—А–Љ–Є—А–Њ–≤–∞–ї—Б—П –љ–µ –љ–∞ –Њ—Б–љ–Њ–≤–µ –≤—Б–µ—Е 256 –≥–∞—А–Љ–Њ–љ–Є–Ї, –∞ —В–Њ–ї—М–Ї–Њ —В–µ—Е, –Ї–Њ—В–Њ—А—Л–µ —Б–Њ—Б—В–∞–≤–ї—П–ї–Є –ї–Њ–Ї–∞–ї—М–љ—Л–µ –Љ–∞–Ї—Б–Є–Љ—Г–Љ—Л –≤ —В–µ—З–µ–љ–Є–Є –Ї–∞–і—А–∞. –≠—В–Њ –њ–µ—А–≤–Њ–µ. –Т—В–Њ—А–Њ–µ вАУ –љ–Є–Ї–∞–Ї–Њ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –Њ —Д–∞–Ј–µ —Б–Є–љ—Г—Б–Њ–≤ –љ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–ї–Њ—Б—М. –Ф–∞, –Ї–∞—З–µ—Б—В–≤–Њ –≤–Њ—Б–њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Є—П –љ–µ —В–∞–Ї–Њ–µ, –Ї–∞–Ї —Г –і–≤–Є–ґ–Ї–Њ–≤ –≤ SAPI 5, –љ–Њ –≤–µ–і—М –Є –Ј–∞–і–∞—З–∞ —Б—В–Њ–Є—В –Є–љ–∞—П вАУ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ. –Ш –њ–Њ—Н—В–Њ–Љ—Г –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –≤—Л–≤–Њ–і, —З—В–Њ –≤ –Љ–∞—Б—Б–Є–≤–µ –і–∞–љ–љ—Л—Е 50X256 –µ—Б—В—М –≤—Б–µ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ–µ –і–ї—П —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П. –Э–µ–Ї–Є–µ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П –љ–∞–і –Љ–∞—Б—Б–Є–≤–Њ–Љ –±—Л–ї–Є —Б–і–µ–ї–∞–љ—Л, –љ–∞–њ—А–Є–Љ–µ—А –Њ–≥–Є–±–∞—О—Й–∞—П, –Ї–Њ—В–Њ—А–∞—П —Б–∞–Љ–∞ –њ–Њ —Б–µ–±–µ —В–Њ–ґ–µ –Є–љ—Д–Њ—А–Љ–∞—В–Є–≤–љ–∞, –љ–Њ –Њ–љ–∞ –±—Л–ї–∞ –њ–Њ–ї—Г—З–µ–љ–∞ –Є–Ј —В–Њ–≥–Њ –ґ–µ –Љ–∞—Б—Б–Є–≤–∞ –±–µ–Ј –њ—А–Є–≤–ї–µ—З–µ–љ–Є—П —Б—В–Њ—А–Њ–љ–љ–µ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є.
- –Ъ–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ—Л–є –Љ–µ—В–Њ–і –љ–µ–Њ–±—Е–Њ–і–Є–Љ, –љ–Њ –љ–µ –і–Њ—Б—В–∞—В–Њ—З–µ–љ. –Ч–≤—Г—З–∞–љ–Є–µ –њ–Њ—Е–Њ–ґ–Є—Е —Б–ї–Њ–≤ –Њ—Ж–µ–љ–Є–≤–∞–µ—В—Б—П –Ї–∞–Ї 50% -–µ —Б–Њ–≤–њ–∞–і–µ–љ–Є–µ.
- –Ю—Ж–µ–љ–Ї–∞ –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–Њ–≤ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Є —А–∞–Ј–љ–Њ—Б—В–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є –≥–∞—А–Љ–Њ–љ–Є–Ї –Љ–∞–ї–Њ –Є–љ—Д–Њ—А–Љ–∞—В–Є–≤–љ–∞, —В–µ–Љ –±–Њ–ї–µ–µ –Є—Е —Б—А–µ–і–љ–µ–µ.
–Ф–∞–ї—М–љ–µ–є—И–µ–µ –љ–∞–њ—А–∞–≤–ї–µ–љ–Є–µ, —З—В–Њ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є–Љ —Б–њ–Њ—Б–Њ–±–Њ–Љ.
- –Э–∞–і –Њ–≥–Є–±–∞—О—Й–µ–є —В–∞–Ї –ґ–µ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М —Б–њ–µ–Ї—В—А–∞–ї—М–љ–Њ–µ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ. –≠—В–Њ –Љ–Њ–ґ–µ—В –±—Л—В—М –њ–Њ–Є–љ—В–µ—А–µ—Б–љ–µ–є, —З–µ–Љ –Ї–µ–њ—Б—В—А–∞–ї—М–љ—Л–µ –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В—Л[6].
- –Ш–љ—В–µ—А–µ—Б–љ–Њ, –Ї–∞–Ї –њ–Њ–Ї–∞–Ј—Л–≤–∞—О—В –љ–µ–Ї–Њ—В–Њ—А—Л–µ –∞–≤—В–Њ—А—Л[7], –њ—А–Є–Љ–µ–љ–Є—В—М –Ї –Ї–∞–і—А–∞–Љ —Д–Є–ї—М—В—А –Ъ–∞–ї–Љ–∞–љ–∞[8]. –Ш –љ–∞ —Н—В–Њ–є –Њ—Б–љ–Њ–≤–µ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞—В—М —Д–Њ–љ–µ–Љ—Л.
- –Э—Г, –Є –љ–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є –љ–Є–Ї—В–Њ –љ–µ –Њ—В–Љ–µ–љ—П–ї.
- –Т –Њ—В–ї–Є—З–Є–µ –Њ—В —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Њ–±—Л—З–љ–Њ–≥–Њ –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є—П, —Б–Њ–љ–∞—А–љ–∞—П –Ї–∞—А—В–Є–љ–∞, –Ї–Њ—В–Њ—А–∞—П –њ–Њ–Ї–∞–Ј–∞–љ–∞ –љ–∞ –†–Є—Б.2, –Є–Љ–µ–µ—В —В—А–Є –Є–љ–≤–∞—А–Є–∞–љ—В–љ—Л—Е –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П. –°–ї–Њ–≤–Њ –Љ–Њ–ґ–љ–Њ –њ—А–Њ–Є–Ј–љ–µ—Б—В–Є –±—Л—Б—В—А–Њ –Є–ї–Є –Љ–µ–і–ї–µ–љ–љ–Њ –Є —Б —А–∞–Ј–љ—Л–Љ —В–Њ–љ–Њ–Љ. –≠—В–Њ –Њ—В—А–∞–ґ–∞–µ—В—Б—П –љ–∞ —Б–Њ–љ–∞—А–љ–Њ–є –Ї–∞—А—В–Є–љ–µ, –Ї–∞–Ї –Є–Ј–Љ–µ–љ–µ–љ–Є–µ –њ–Њ –Њ—Б–Є X –Є Y, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ. –Я–Њ—Н—В–Њ–Љ—Г –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М —Н—В–∞–њ—Л –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ–Њ–≥–Њ –Љ–∞—Б—И—В–∞–±–Є—А–Њ–≤–∞–љ–Є—П –њ–∞—В—В–µ—А–љ–∞ –≤ –њ—А–Њ—Ж–µ—Б—Б–µ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ–Њ–≥–Њ –∞–љ–∞–ї–Є–Ј–∞. –У—А–Њ–Љ–Ї–Њ—Б—В—М –њ—А–Њ–Є–Ј–љ–µ—Б–µ–љ–љ–Њ–≥–Њ —Б–ї–Њ–≤–∞ —В–∞–Ї –ґ–µ –≤–ї–Є—П–µ—В –љ–∞ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ—Л–µ –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В—Л, –њ–Њ—Н—В–Њ–Љ—Г –Љ–Њ–ґ–љ–Њ –њ—А–Є–Љ–µ–љ–Є—В—М –љ–Њ—А–Љ–∞–ї–Є–Ј–∞—Ж–Є—О –њ–Њ –∞–Љ–њ–ї–Є—В—Г–і–µ –≥–∞—А–Љ–Њ–љ–Є–Ї.
- –Ш–љ—В–µ—А–µ—Б–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л –Љ–Њ–ґ–µ—В –і–∞—В—М –Љ–µ—В–Њ–і –±–Є–љ–∞—А–Є–Ј–∞—Ж–Є–Є. –Э–∞ –µ–≥–Њ –Њ—Б–љ–Њ–≤–µ –Љ–Њ–ґ–љ–Њ –њ–Њ–ї—Г—З–Є—В—М –≤—Б–µ –і–∞–љ–љ—Л–µ –і–ї—П –љ–Њ—А–Љ–∞–ї–Є–Ј–∞—Ж–Є–Є –Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є—П –њ–Њ X –Є Y. –Р –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ—Г—О –Њ–±—А–∞–±–Њ—В–Ї—Г –Љ–Њ–ґ–љ–Њ –і–µ–ї–∞—В—М –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ —Б–ї–Њ—П, –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –≤—Л—З–Є—Б–ї–µ–љ–Є–µ –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–∞ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Є –≤—Л—А–Њ–ґ–і–∞–µ—В—Б—П –≤ –Њ–±—Л—З–љ–Њ–µ —Б–Њ–≤–њ–∞–і–µ–љ–Є–µ.
- –Ь–µ—В–Њ–і —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П —Б –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ–Љ –њ–∞—В—В–µ—А–љ–Њ–≤ –Љ–Њ–ґ–µ—В –њ–Њ—В—А–µ–±–Њ–≤–∞—В—М –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ–є –њ–∞–Љ—П—В–Є –Є –±—Л—Б—В—А–Њ–і–µ–є—Б—В–≤–Є—П, –µ—Б–ї–Є –Ј–∞–њ–Њ–Љ–Є–љ–∞—В—М —Б–ї–Њ–≤–∞. –Я–Њ—Н—В–Њ–Љ—Г –Љ–љ–Њ–≥–Є–µ –∞–≤—В–Њ—А—Л –њ—А–µ–і–ї–∞–≥–∞—О—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ —Д–Њ–љ–µ–Љ. –С–Є–±–ї–Є–Њ—В–µ–Ї–∞ —Д–Њ–љ–µ–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М –Ј–љ–∞—З–Є—В–µ–ї—М–љ–Њ –Љ–µ–љ—М—И–µ –њ–Њ —А–∞–Ј–Љ–µ—А—Г.
 
–Э–µ–Љ–љ–Њ–≥–Њ –Њ–± –Є–љ–Њ–Љ –њ—Г—В–Є.
–Э–∞ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В —П –њ—А–µ–і–ї–Њ–ґ—Г –≥–Є–њ–Њ—В–µ–Ј—Г, —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П –Ї–Њ—В–Њ—А–Њ–є —В–Њ–ї—М–Ї–Њ –љ–∞–Љ–µ—В–Є–ї–∞—Б—М. –Х—Б–ї–Є —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞—В—М —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ, –Ї–∞–Ї –Ї–Њ–љ–µ—З–љ—Г—О –Ј–∞–і–∞—З—Г –Љ–Њ–і–µ–ї–Є, —В–Њ –≤ —Н—В–Њ–Љ –њ—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ –Є –µ—Б—В—М —Б—Г—В—М —Г—Б–ї–Њ–≤–љ–Њ–≥–Њ –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–≥–Њ –Љ–µ—В–Њ–і–∞. –Э–Њ –Љ–Њ–ґ–љ–Њ –њ—А–µ–і–њ–Њ–ї–Њ–ґ–Є—В—М, —З—В–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ —Н—В–Њ –≤—Б–µ–≥–Њ –љ–∞–≤—Б–µ–≥–Њ –і–µ–є—Б—В–≤–Є–µ, –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ–µ –і–ї—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є —Ж–µ–ї–µ–≤–Њ–є —Д—Г–љ–Ї—Ж–Є–Є. –Ъ–∞–Ї –Љ–Њ–ґ–љ–Њ –Њ–±–Њ–Ј–љ–∞—З–Є—В—М —В–∞–Ї—Г—О —Ж–µ–ї–µ–≤—Г—О —Д—Г–љ–Ї—Ж–Є—О? –Ю–± —Н—В–Њ–Љ —Г–ґ–µ –љ–µ —А–∞–Ј –≥–Њ–≤–Њ—А–Є–ї–Њ—Б—М –љ–∞ —Д–Њ—А—Г–Љ–µ:
http://www.gotai.net/forum/Default.aspx?postid=57100#57100
–¶–µ–ї–µ–≤–∞—П —Д—Г–љ–Ї—Ж–Є—П —Б–Є—Б—В–µ–Љ—Л —Н—В–Њ –њ–Њ–Є—Б–Ї –≤ –љ–µ–њ—А–µ—А—Л–≤–љ–Њ–Љ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Њ–љ–љ–Њ–Љ –њ–Њ—В–Њ–Ї–µ –љ–Њ–≤–Є–Ј–љ—Л.
–Э–Њ –њ–Њ–Ї–∞ –Љ—Л –љ–µ –±—Г–і–µ–Љ –≤–і–∞–≤–∞—В—М—Б—П –≤ —А–∞—Б—Б—Г–ґ–і–µ–љ–Є—П –Њ —В–Њ–Љ, —З—В–Њ –њ–Њ—В–Њ–Ї, –µ—Б–ї–Є —Н—В–Њ –љ–µ –±–µ–ї—Л–є —И—Г–Љ, –Є–Љ–µ–µ—В —Б—В—А—Г–Ї—В—Г—А—Г, –Ї–Њ—В–Њ—А–∞—П –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ –Љ–Њ–ґ–µ—В –±—Л—В—М –Њ—В—А–∞–ґ–µ–љ–∞ –≤ —Б—В—А—Г–Ї—В—Г—А–µ –Љ–Њ–і–µ–ї–Є. –Э–∞ –і–∞–љ–љ–Њ–Љ —Н—В–∞–њ–µ —Б—В–∞–≤–Є—В—Б—П –Ј–∞–і–∞—З–∞ –Њ—Ж–µ–љ–Є—В—М —Б–ї–Њ–ґ–љ–Њ—Б—В—М –њ—А–Њ–≥—А–∞–Љ–Љ–љ–Њ–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –њ–∞–Љ—П—В–Є –њ–µ—А–≤–Њ–≥–Њ —Г—А–Њ–≤–љ—П, –Њ—Ж–µ–љ–Є—В—М –Њ–±—К–µ–Љ —Н—В–Њ–є –њ–∞–Љ—П—В–Є –Є —Б–Ї–Њ—А–Њ—Б—В—М –Љ–∞–љ–Є–њ—Г–ї—П—Ж–Є–Є –і–∞–љ–љ—Л–Љ–Є –њ—А–Є —Б—А–∞–≤–љ–µ–љ–Є–Є.
–І—В–Њ –Є–Ј —Б–µ–±—П –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В —А–µ—З–µ–≤–Њ–є –њ–Њ—В–Њ–Ї? –Т —А–∞–Љ–Ї–∞—Е –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–љ–Њ–є –њ—А–Њ–≥—А–∞–Љ–Љ—Л вАУ —Н—В–Њ –љ–µ–њ—А–µ—А—Л–≤–љ–Њ–µ —З–µ—А–µ–і–Њ–≤–∞–љ–Є–µ –Ї–∞–і—А–Њ–≤. –Т –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ –Ї–∞–і—А, —Б–Њ–і–µ—А–ґ–∞—Й–Є–є —А–µ–∞–ї–Є–Ј–∞—Ж–Є—О –∞–Љ–њ–ї–Є—В—Г–і –≥–∞—А–Љ–Њ–љ–Є–Ї, - –±—Г–і–µ—В —Б–∞–Љ—Л–Љ –љ–Є–Ј–Ї–Њ—Г—А–Њ–≤–љ–µ–≤—Л–Љ –Ї–ї–∞—Б—В–µ—А–Њ–Љ. –§–Њ–љ–µ–Љ–∞ –±—Г–і–µ—В –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ–Љ –Ї–∞–і—А–Њ–≤. –°–ї–Њ–≤–Њ вАУ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ —Д–Њ–љ–µ–Љ. –§—А–∞–Ј–∞ вАУ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ —Б–ї–Њ–≤. –Р–±—Б—В—А–∞–Ї—В–љ–Њ–µ –њ–Њ–љ—П—В–Є–µ –Њ–њ–Є—Б—Л–≤–∞–µ—В—Б—П –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ–Љ —Д—А–∞–Ј. –Я—П—В—М –Ї–ї–∞—Б—В–µ—А–Њ–≤. –Ъ–∞–ґ–і–Њ–Љ—Г –Ї–ї–∞—Б—В–µ—А—Г —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В —Б–≤–Њ–є —Г—А–Њ–≤–µ–љ—М –њ–∞–Љ—П—В–Є. –Ъ–∞–ґ–і—Л–є —Г—А–Њ–≤–µ–љ—М —А–µ–∞–ї–Є–Ј—Г–µ—В —Ж–µ–ї–µ–≤—Г—О —Д—Г–љ–Ї—Ж–Є—О. –Т —А–∞–Љ–Ї–∞—Е –њ—А–Њ–±–ї–µ–Љ—Л –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–≥–Њ –Є–љ—В–µ–ї–ї–µ–Ї—В–∞ –≤ –і–∞–љ–љ–Њ–є —Б—В–∞—В—М–µ –Љ–Њ–ґ–љ–Њ –Њ–≥—А–∞–љ–Є—З–Є—В—М—Б—П —Г–Ј–Ї–Њ–є –Ј–∞–і–∞—З–µ–є –љ–∞ —Г—А–Њ–≤–љ–µ —Д–Њ–љ–µ–Љ. –Я—Г—Б—В—М –Ј–∞–і–∞—З–∞ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П —Д–Њ–љ–µ–Љ –±—Г–і–µ—В –Њ–њ—А–µ–і–µ–ї—П—В—М –Ї–Њ–љ–µ—З–љ—Г—О —Б—В—А—Г–Ї—В—Г—А—Г –Љ–Њ–і–µ–ї–Є. –≠—В–Њ –±—Г–і–µ—В –Њ–Ј–љ–∞—З–∞—В—М, —З—В–Њ –Ї–Њ–≥–і–∞ –ї—О–±–Њ–є —З–µ–ї–Њ–≤–µ–Ї –њ—А–Њ–Є–Ј–љ–Њ—Б–Є—В —Б–ї–Є—В–љ—Г—О —А–µ—З—М, –Љ–Њ–і–µ–ї—М –і–Њ–ї–ґ–љ–∞ –Њ–њ—А–µ–і–µ–ї–Є—В—М –≤—Б–µ —Д–Њ–љ–µ–Љ—Л –Є –Є—Е —З–µ—А–µ–і–Њ–≤–∞–љ–Є–µ. –≠—В–Њ —Ж–µ–ї—М, –∞ –њ–Њ–Ї–∞ –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л.
 
–†–∞—Б—Б–Љ–Њ—В—А–Є–Љ —Б–∞–Љ—Л–є –љ–Є–Ј–Ї–Є–є —Г—А–Њ–≤–µ–љ—М.
–Я–∞—А–∞–Љ–µ—В—А—Л –Ї–ї–∞—Б—В–µ—А–∞: –і–ї–Є—В–µ–ї—М–љ–Њ—Б—В—М вАУ 40 –Љ—Б, –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –Ј–љ–∞—З–µ–љ–Є–є вАУ 256, –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є–є –і–Є–∞–њ–∞–Ј–Њ–љ 0..255. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –Ї–∞–і—А –Љ–Њ–ґ–љ–Њ –њ—А–µ–і—Б—В–∞–≤–Є—В—М –≤ –≤–Є–і–µ –љ–∞–±–Њ—А–∞ –і–≤—Г—Е–±–∞–є—В–Њ–≤—Л—Е –Ј–љ–∞—З–µ–љ–Є–є: —Б—В–∞—А—И–Є–є –±–∞–є—В вАУ –љ–Њ–Љ–µ—А –≥–∞—А–Љ–Њ–љ–Є–Ї–Є, –Љ–ї–∞–і—И–Є–є вАУ –∞–Љ–њ–ї–Є—В—Г–і–∞. –Ґ–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є —А–∞–Ј–Љ–µ—А —Н—В–Њ–≥–Њ –љ–∞–±–Њ—А–∞ –Њ–≥—А–Њ–Љ–µ–љ, –љ–Њ –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –µ–≥–Њ –Љ–Њ–ґ–љ–Њ –Њ—Ж–µ–љ–Є—В—М –≤ –≤–µ—Б—М–Љ–∞ –њ—А–Є–µ–Љ–ї–µ–Љ—Г—О —Ж–Є—Д—А—Г. –Ъ–Њ–≥–і–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В—Б—П –Ј–∞–њ–Є—Б—М –≤ –њ—А–Њ–≥—А–∞–Љ–Љ–µ, —В–Њ –≤ —В–µ–Ї—Б—В–Њ–≤–Њ–Љ –њ–Њ–ї–µ –≤—Л–≤–Њ–і–Є—В—Б—П –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –∞–Ї—В–Є–≤–љ—Л—Е –≥–∞—А–Љ–Њ–љ–Є–Ї (—Б–Љ. –†–Є—Б 1). –Ш —Н—В–Њ —З–Є—Б–ї–Њ –Љ–µ–љ–µ–µ —В—Л—Б—П—З–Є. –Ш —В–∞–Ї –ґ–µ, —Н—В–Њ —З–Є—Б–ї–Њ –∞–Ї—В–Є–≤–љ—Л—Е –≥–∞—А–Љ–Њ–љ–Є–Ї –љ–µ –≤ –Њ–і–љ–Њ–Љ –Ї–∞–і—А–µ, –∞ –≤–Њ –≤—Б–µ–є —Д—А–∞–Ј–µ.
–Ф–∞–ї—М–љ–µ–є—И–µ–µ –Њ–њ–Є—Б–∞–љ–Є–µ –Љ–Њ–ґ–µ—В —Г—В–Њ–Љ–Є—В—М, —В–∞–Ї –Ї–∞–Ї —Б–ї–Њ–ґ–љ–Њ –Њ–њ–Є—Б–∞—В—М –≤–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤–Є–µ –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є—Е –Љ–∞—Б—Б–Є–≤–Њ–≤ –Є –Є—Е –Є–љ–і–µ–Ї—Б—Л. –Э–Њ —П –њ–Њ–њ—Л—В–∞—О—Б—М, –њ–∞–Љ—П—В—Г—П –Њ —В–Њ–Љ, —З—В–Њ –µ—Б—В—М —В–µ–Ї—Б—В—Л –њ—А–Њ–≥—А–∞–Љ–Љ—Л, –Њ–љ–Є –Љ–Њ–≥—Г—В –±–Њ–ї—М—И–µ —Б–Ї–∞–Ј–∞—В—М, –Њ—Б–Њ–±–µ–љ–љ–Њ –≤ —А–µ–ґ–Є–Љ–µ –Њ—В–ї–∞–і–Ї–Є. –°–Ї–∞–ґ—Г —З–µ—Б—В–љ–Њ, —З—В–Њ —Б–∞–Љ, —А–∞–±–Њ—В–∞—П –≤ –і–µ–±–∞–≥–µ—А–µ, —А–∞—Б–њ—А—П–Љ–Є–ї —Б–µ–±–µ –љ–µ –Њ–і–љ—Г –Є–Ј–≤–Є–ї–Є–љ—ГвА¶
–Ш —В–∞–Ї, –Љ–Њ–ґ–љ–Њ –Њ–њ–Є—Б–∞—В—М –њ–µ—А–≤—Л–є —Г—А–Њ–≤–µ–љ—М –њ–∞–Љ—П—В–Є (—Б–Љ. –Љ–Њ–і—Г–ї—М UnitMem):
type Tmem = array of word;type THarmAmpl = array of word;
type TmemLevelData = array of THarmAmpl;
type
private
public
Data: TmemLevelData;
Same: array of array[0..1] of word;
SortNum: array [0..DFT_kmax-1] of Tmem;
size: TAgentParam
constructor Create(level:TAgentParam);
procedure Sleep;
procedure AddData(indat: TmemLevelData; start,stop:integer);
end;
Data вАУ –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є–є –Љ–∞—Б—Б–Є–≤ —Г–њ–∞–Ї–Њ–≤–∞–љ–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є:
K:=Hi(Data[n][k]) вАУ –љ–Њ–Љ–µ—А –≥–∞—А–Љ–Њ–љ–Є–Ї–Є;A:=Lo(Data[n][k]) вАУ –∞–Љ–њ–ї–Є—В—Г–і–∞ –≤ –і–Є–∞–њ–∞–Ј–Њ–љ–µ 0..255;
–Ъ–∞–і—А –Љ–Њ–ґ–µ—В —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є —Б–Њ–і–µ—А–ґ–∞—В—М –Љ–∞–Ї—Б–Є–Љ—Г–Љ 255 —В–∞–Ї–Є—Е –Ј–љ–∞—З–µ–љ–Є–є. –Я—А–Є —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –њ—А–Њ—Ж–µ—Б—Б–∞ –Ј–∞–њ–Є—Б–Є –Љ–∞—Б—Б–Є–≤ Data –њ–Њ –Њ—З–µ—А–µ–і–Є –Ј–∞–њ–Њ–ї–љ—П–µ—В—Б—П –љ–µ–њ–Њ–≤—В–Њ—А—П—О—Й–Є–Љ–Є—Б—П –Ї–∞–і—А–∞–Љ–Є. –Я–Њ—П—Б–љ—О —В–∞–Ї –ґ–µ, —З—В–Њ —Б–Њ—А—В–Є—А–Њ–≤–∞—В—М –Є –њ–µ—А–µ–Љ–µ—Й–∞—В—М —В–∞–Ї–Њ–є –Љ–∞—Б—Б–Є–≤ –љ–µ –њ—А–∞–≤–Є–ї—М–љ–Њ. –≠—В–Њ—В –Љ–∞—Б—Б–Є–≤ —В–Њ–ї—М–Ї–Њ –њ–Њ–њ–Њ–ї–љ—П–µ—В—Б—П –љ–Њ–≤—Л–Љ–Є —Д—А–∞–≥–Љ–µ–љ—В–∞–Љ–Є.
–°—А–∞–≤–љ–Є–≤–∞—В—М –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї —В–Њ–ї—М–Ї–Њ —В–µ –Љ–∞—Б—Б–Є–≤—Л, –Ї–Њ—В–Њ—А—Л–µ –Є–Љ–µ—О—В –Њ–і–Є–љ–∞–Ї–Њ–≤—Л–є —А–∞–Ј–Љ–µ—А. –І—В–Њ–±—Л –љ–µ –њ–µ—А–µ–±–Є—А–∞—В—М –≤–µ—Б—М –Љ–∞—Б—Б–Є–≤ Data –њ—А–Є —Б—А–∞–≤–љ–µ–љ–Є–Є —Б—Г—Й–µ—Б—В–≤—Г–µ—В –Љ–∞—Б—Б–Є–≤ SortNum. –Я–Њ —Б—Г—В–Є —Н—В–Њ 256, –њ–Њ —З–Є—Б–ї—Г –≥–∞—А–Љ–Њ–љ–Є–Ї, –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є—Е –Љ–∞—Б—Б–Є–≤–Њ–≤. –Ю–љ –Ј–∞–њ–Њ–ї–љ—П–µ—В—Б—П —Б–Є–љ—Е—А–Њ–љ–љ–Њ —Б –Љ–∞—Б—Б–Є–≤–Њ–Љ Data.
–Ч–љ–∞—З–µ–љ–Є–µ —Н—В–Њ–≥–Њ –Љ–∞—Б—Б–Є–≤–∞ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Є–љ–і–µ–Ї—Б—Г –Љ–∞—Б—Б–Є–≤–∞ Data.
–Т–Њ—В —Д—А–∞–≥–Љ–µ–љ—В –њ–Њ—Б–ї–µ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –Ј–∞–њ–Є—Б–µ–є:
SortNum = ((), (), (), (), (), (), (), (), (), (), (), (8), (3), (5), (2), (0, 6, 9), (1, 4), (7)вА¶);
Data = ((1372, 2324, 3615, 4894, 5926, 7295, 8577, 9602, 10632, 11130, 13085, 16651, 20237, 22552, 26120), (271, 1409, 3863, 5162, 6480, 7467, 7986, 9177, 9853, 11338, 11796, 13077, 13843, 14860, 15632, 22027), (1626, 2864, 4379, 7229, 8554, 9241, 10094, 11304, 13837, 15633, 19723, 21769, 25609, 27150), (1691, 2906, 4386, 7246, 8756, 10100, 11556, 12296, 15888, 21775, 23052, 28170), (523, 1460, 2852, 4143, 4626, 5789, 7010, 8386, 9926, 11137, 12297, 13597, 14856, 16654, 19215, 22029), (1353, 2582, 3867, 4914, 6277, 7481, 8824, 9877, 11435, 13603, 17417, 23055, 27406), (1329, 2319, 4908, 5945, 7180, 8069, 8605, 9522, 10594, 11555, 13154, 15373, 19981, 21257, 26120), (1345, 2339, 3600, 4649, 5924, 8379, 9487, 10519, 12043, 12832, 14347, 15425, 16654, 17677, 18703, 24615, 37385), (1340, 2335, 3609, 4639, 5652, 8230, 8718, 10768, 14092, 15627, 19213), (261, 1345, 3621, 4889, 6033, 7264, 8341, 9653, 10950, 11544, 12058, 13067, 16656, 21521, 26123));
–Ф–∞–љ–љ–∞—П –Ј–∞–њ–Є—Б—М –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ —Н–ї–µ–Љ–µ–љ—В –Љ–∞—Б—Б–Є–≤–∞ Data —Б –Є–љ–і–µ–Ї—Б–Њ–Љ 8 —Б–Њ–і–µ—А–ґ–Є—В 11 –њ–Њ–≤—В–Њ—А–Њ–≤ —Г–њ–∞–Ї–Њ–≤–∞–љ–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є –≤ –Ї–∞–і—А–µ, –∞ —Н–ї–µ–Љ–µ–љ—В—Л 0,6,9 вАУ –Є–Љ–µ—О—В –њ–Њ 15 –њ–Њ–≤—В–Њ—А–Њ–≤ –≤ —В–µ—З–µ–љ–Є–Є –≤—Б–µ–≥–Њ –≤—А–µ–Љ–µ–љ–Є —Н–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В—Л.
Same вАУ —Н–ї–µ–Љ–µ–љ—В—Л —Н—В–Њ–≥–Њ –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Њ–≥–Њ –Љ–∞—Б—Б–Є–≤–∞, –њ—А–µ–і—Б—В–∞–≤–ї—П—О—В –Є–Ј —Б–µ–±—П –і–≤–∞ —З–Є—Б–ї–∞, –њ–µ—А–≤–Њ–µ вАУ –Є–љ–і–µ–Ї—Б –Љ–∞—Б—Б–Є–≤–∞ Data, –≤—В–Њ—А–Њ–µ вАУ –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –њ–Њ–≤—В–Њ—А–Њ–≤ –њ—А–Є –њ–Њ—Н–ї–µ–Љ–µ–љ—В–љ–Њ–Љ —Б—А–∞–≤–љ–µ–љ–Є–Є. –Э–∞–њ—А–Є–Љ–µ—А, Data[0] вАУ –Љ–∞—Б—Б–Є–≤, –Ї–Њ—В–Њ—А—Л–є —Б–Њ–і–µ—А–ґ–Є—В 15 —Н–ї–µ–Љ–µ–љ—В–Њ–≤. –Я–Њ–≤—В–Њ—А, —Н—В–Њ –Ї–Њ–≥–і–∞ —В–Њ—З–љ–Њ —В–∞–Ї–∞—П –ґ–µ —А–µ–∞–ї–Є–Ј–∞—Ж–Є—П —Б–ї—Г—З–Є—В—Б—П –≤ –њ—А–Њ—Ж–µ—Б—Б–µ –Ј–∞–њ–Є—Б–Є. –Ь–Њ–ґ–љ–Њ –і—Г–Љ–∞—В—М, —З—В–Њ —Н—В–Њ —А–µ–і—З–∞–є—И–µ–µ —Б–Њ–±—Л—В–Є–µвА¶
Size вАУ –њ–Њ–ї–µ –Є–љ–і–Є–Ї–∞—В–Њ—А —Г—А–Њ–≤–љ—П –њ–∞–Љ—П—В–Є. –Т –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ —А–∞–≤–љ–Њ 1. –≠—В–Њ –Ј–љ–∞—З–Є—В, —З—В–Њ —А–∞–±–Њ—В–∞ –Є–і–µ—В —Б –Њ–і–љ–Є–Љ –Ї–∞–і—А–Њ–Љ.
–Ш —В–∞–Ї, –і–∞–љ–љ–∞—П —Б—В—А—Г–Ї—В—Г—А–∞ –Ј–∞–њ–Њ–ї–љ—П–µ—В—Б—П –љ–µ –њ–Њ–≤—В–Њ—А—П—О—Й–Є–Љ–Є—Б—П –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є—П–Љ–Є. –Я—А–Њ–Є—Б—Е–Њ–і–Є—В —Н—В–Њ –њ—А–Є –Ї–∞–ґ–і–Њ–Љ –љ–∞–ґ–∞—В–Є–Є –Ї–љ–Њ–њ–Ї–Є Record. –ѓ –љ–µ –Љ–Њ–≥—Г —Б–µ–±–µ –њ—А–µ–і—Б—В–∞–≤–Є—В—М, —З—В–Њ —Н—В–Њ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –∞–њ—А–Є–Њ—А–љ–Њ —Б —А–∞–љ–і–Њ–Љ–∞–є–Ј–Є–љ–≥–Њ–Љ, —В–∞–Ї –Ї–∞–Ї –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є–Є –Ј–љ–∞—З–µ–љ–Є–є —Б–Є–ї—М–љ–Њ –Ј–∞–≤–Є—Б—П—В –Њ—В –њ—А–µ–і—Г—Б—В–∞–љ–Њ–≤–ї–µ–љ–љ—Л—Е –њ–∞—А–∞–Љ–µ—В—А–Њ–≤ —Д–Є–ї—М—В—А–Њ–≤ –Є —А–∞–Ј–ї–Є—З–љ—Л—Е —Г—А–Њ–≤–љ–µ–є —В—А–Є–≥–≥–µ—А–Њ–≤. –Ш –≤–њ–Њ–ї–љ–µ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, —З—В–Њ –Ї–∞–Ї–Є–µ-—В–Њ –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є–Є –≤–Њ–Њ–±—Й–µ –љ–µ –±—Г–і–µ—В —А–µ–∞–ї–Є–Ј–Њ–≤–∞–љ—Л. –Э–∞–њ—А–Є–Љ–µ—А, –Ј–љ–∞—З–µ–љ–Є—П —Б –≤—Л—Б–Њ–Ї–Є–Љ–Є –≥–∞—А–Љ–Њ–љ–Є–Ї–∞–Љ–Є. –Ш —Н—В–Њ –µ—Б—В—М –∞–њ—А–Є–Њ—А–љ–Њ–µ –Ј–љ–∞–љ–Є–µ, —Е–∞—А–∞–Ї—В–µ—А–љ–Њ–µ –Є–Љ–µ–љ–љ–Њ –і–ї—П —А–µ—З–Є, –Ї–Њ—В–Њ—А–Њ–µ –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –і–ї—П –і–∞–ї—М–љ–µ–є—И–µ–≥–Њ —Г–Љ–µ–љ—М—И–µ–љ–Є—П –Љ–∞—Б—Б–Є–≤–∞ –Є –њ–Њ–≤—Л—И–µ–љ–Є—П –±—Л—Б—В—А–Њ–і–µ–є—Б—В–≤–Є—П. –Ч–∞–Љ–µ—В—М—В–µ, —З—В–Њ –≤—Б–µ —И–Є–њ—П—Й–Є–µ –Ј–≤—Г–Ї–Є —Д–∞–Ї—В–Є—З–µ—Б–Ї–Є ¬Ђ—И–Є–њ—П—В¬ї –Њ–і–Є–љ–∞–Ї–Њ–≤–Њ. –Э—Г, –њ–Њ –Ї—А–∞–є–љ–µ–є –Љ–µ—А–µ, —А–∞–Ј–љ–Њ–Њ–±—А–∞–Ј–Є—П –≤ —Н—В–Њ–Љ ¬Ђ—И–Є–њ–µ¬ї –љ–µ —В–∞–Ї —Г–ґ –Є –Љ–љ–Њ–≥–Њ.
–Я—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л —Н–Ї—Б–њ–µ—А–Є–Љ–µ–љ—В–∞.
–Т–љ–∞—З–∞–ї–µ –≤—Л—Б—В–∞–≤–ї—П–µ–Љ –њ—А–Є–µ–Љ–ї–µ–Љ–Њ–µ –Ј–љ–∞—З–µ–љ–Є–µ –≤—Б–µ—Е —Г—А–Њ–≤–љ–µ–є –Є —Д–Є–ї—М—В—А–Њ–≤. –°—Г–±—К–µ–Ї—В–Є–≤–љ–Њ. –Ч–∞—В–µ–Љ –љ–∞–ґ–Є–Љ–∞–µ–Љ Record –Є –њ—А–Њ–Є–Ј–љ–Њ—Б–Є–Љ –Њ–і–љ–Њ —Б–ї–Њ–≤–Њ —Б —А–∞–Ј–љ—Л–Љ–Є –Є–љ—В–Њ–љ–∞—Ж–Є—П–Љ–Є –Є –≥—А–Њ–Љ–Ї–Њ—Б—В—М—О. –Ч–∞—В–µ–Љ –њ–Њ—Е–Њ–ґ–µ–µ –њ–Њ –Ј–≤—Г—З–∞–љ–Є—О —Б–ї–Њ–≤–ЊвА¶ –Я—А–Є –Ї–∞–ґ–і–Њ–є –Ј–∞–њ–Є—Б–Є –≤ —В–µ–Ї—Б—В–Њ–≤–Њ–Љ –њ–Њ–ї–µ –≤—Л–≤–Њ–і–Є—В—Б—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П:
- –Ь–∞—Б—Б–Є–≤–Њ–≤ –њ–∞–Љ—П—В–Є: 45 - –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ —Н–ї–µ–Љ–µ–љ—В–Њ–≤ –Љ–∞—Б—Б–Є–≤–∞ Data;
- –Ь–∞—Б—Б–Є–≤–Њ–≤ —Б –њ–Њ–≤—В–Њ—А–∞–Љ–Є: 2 - –Ї–Њ–ї–Є—З–µ—Б—В–≤–Њ –∞–±—Б–Њ–ї—О—В–љ–Њ –Њ–і–Є–љ–∞–Ї–Њ–≤—Л—Е –Љ–∞—Б—Б–Є–≤–Њ–≤;
- –Я–∞–Љ—П—В–Є: 1124 - —А–∞–Ј–Љ–µ—А –Љ–∞—Б—Б–Є–≤–∞ Data –≤ –±–∞–є—В–∞—Е;
- –Я–Њ–≤—В–Њ—А—Л —Б –і–ї–Є–љ–∞–Љ–Є: ,13,12 - –љ–∞–Є–±–Њ–ї–µ–µ –њ–Њ–њ—Г–ї—П—А–љ—Л–µ –і–ї–Є–љ—Л –Љ–∞—Б—Б–Є–≤–Њ–≤, –Ї–Њ—В–Њ—А—Л–µ –њ–Њ–≤—В–Њ—А—П—О—В—Б—П;
–Я–Њ—Б–ї–µ —Б–Њ—В–љ–Є –љ–∞–ґ–∞—В–Є–є –Є –њ—А–Њ–Є–Ј–љ–µ—Б–µ–љ–Є–є —Б–ї–Њ–≤: –Љ–∞–Љ–∞–љ—П, –і–µ–і–∞, –љ—П–љ—П, –Љ–∞–Љ–∞, –±–∞–±–∞вА¶ –Ї–Њ –Љ–љ–µ –њ–Њ—Б—В—Г—З–∞–ї–Є –Њ–±–µ—Б–њ–Њ–Ї–Њ–µ–љ–љ—Л–µ –і–Њ–Љ–Њ—З–∞–і—Ж—ЛвА¶ –Я–Њ—Б–ї–µ —З–∞—И–Ї–Є –Ї–Њ—Д–µ —П –њ–Њ—Б–Љ–Њ—В—А–µ–ї —Д–∞–є–ї: mamanya_deda_baba.txt
–†–µ–Ј—Г–ї—М—В–∞—В—Г —П —Г–і–Є–≤–Є–ї—Б—П:
- –Ь–∞—Б—Б–Є–≤–Њ–≤ –њ–∞–Љ—П—В–Є: 4012
- –Ь–∞—Б—Б–Є–≤–Њ–≤ —Б –њ–Њ–≤—В–Њ—А–∞–Љ–Є: 2058
- –Я–∞–Љ—П—В–Є: 99170
- –Я–Њ–≤—В–Њ—А—Л —Б –і–ї–Є–љ–∞–Љ–Є: ,13,14,14,15,12,15,15,12,8,11,13вА¶
–І—В–Њ —Н—В–Њ –Ј–љ–∞—З–Є—В?
- 50% –њ–Њ–≤—В–Њ—А–Њ–≤, –Є –Є—Е —З–Є—Б–ї–Њ –±—Г–і–µ—В —А–∞—Б—В–Є;
- 99 –Ї–Є–ї–Њ–±–∞–є—В вАУ —Н—В–Њ –Љ–µ–ї–Њ—З—М;
- –°–Ї–Њ—А–Њ—Б—В—М –њ—А–Є–µ–Љ–ї–µ–Љ–∞—П;
- –Ш–љ—Д–Њ—А–Љ–∞—В–Є–≤–љ–∞—П –і–ї–Є–љ–љ–∞ –Љ–∞—Б—Б–Є–≤–∞ –Њ—В 8 –і–Њ 20;
–Ъ–Њ–љ–µ—З–љ–Њ, —Н—В–Є —А–µ–Ј—Г–ї—М—В–∞—В—Л –њ—А–µ–і–≤–∞—А–Є—В–µ–ї—М–љ—Л–µ. –Э–Њ, –µ—Б—В—М –µ—Й—СвА¶
–Я–Њ—А–Њ—Е –≤ –њ–Њ—А–Њ—Е–Њ–≤–љ–Є—Ж–∞—Е.
–Т –Њ—Б–љ–Њ–≤–µ –Ї–Њ–љ–µ—З–љ–Њ –ї–µ–ґ–Є—В –і–Њ–њ—Г—Й–µ–љ–Є–µ, —З—В–Њ –≤ –Љ–∞—Б—Б–Є–≤–µ 50 –• 256 —В–Њ—З–µ–Ї –µ—Б—В—М –≤—Б—П –љ–µ–Њ–±—Е–Њ–і–Є–Љ–∞—П –Є –і–Њ—Б—В–∞—В–Њ—З–љ–∞—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –і–ї—П —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П. –≠—В–Њ—В –Љ–∞—Б—Б–Є–≤, –њ–Њ –Љ–Њ–µ–Љ—Г –Љ–љ–µ–љ–Є—О, –њ–Њ–ї—Г—З–Є–ї—Б—П –љ–µ –±–Њ–ї—М—И–Є–Љ. –Я–Њ—Н—В–Њ–Љ—Г –µ—Б—В—М –њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є–µ, —З—В–Њ –љ–∞ –Њ—Б–љ–Њ–≤–µ —В–∞–Ї–Њ–є –Љ–µ—В–Њ–і–Є–Ї–Є –њ–Њ –Ј–∞–њ–Њ–ї–љ–µ–љ–Є—О –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Њ–≥–Њ –Љ–∞—Б—Б–Є–≤–∞ –Љ–Њ–ґ–љ–Њ –±—Г–і–µ—В –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ –њ–µ—А–µ–є—В–Є –Њ—В –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Ї —Д–∞–Ї—В–Є—З–µ—Б–Ї–Њ–Љ—Г –љ–∞—Е–Њ–ґ–і–µ–љ–Є—О —Г–ґ–µ –Є–Љ–µ—О—Й–Є—Е—Б—П –љ–∞–Ї–Њ–њ–ї–µ–љ–љ—Л—Е –і–∞–љ–љ—Л—Е –±–µ–Ј –њ—А–Є–≤–ї–µ—З–µ–љ–Є—П –Љ–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є—Е —Г—Е–Є—Й—А–µ–љ–Є–є.
–Ь—Л—Б–ї–Є –≤—Б–ї—Г—Е:
–Р –Ї—В–Њ —Б–Ї–∞–Ј–∞–ї, —З—В–Њ –Љ–∞—Б—Б–Є–≤—Л —А–∞–Ј–љ–Њ–є –і–ї–Є–љ—Л –љ–µ–ї—М–Ј—П —Б—А–∞–≤–љ–Є–≤–∞—В—М? –Ь–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М –Њ—Ж–µ–љ–Ї—Г —Б—А–∞–≤–љ–µ–љ–Є—П –Љ–∞–ї–Њ–≥–Њ –Љ–∞—Б—Б–Є–≤–∞ —Б —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–µ–є —З–∞—Б—В—М—О –±–Њ–ї—М—И–Њ–≥–Њ, —В–µ–Љ –±–Њ–ї–µ–µ, —З—В–Њ —Г–њ–∞–Ї–Њ–≤–∞–љ–љ—Л–µ —В–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ –Ј–љ–∞—З–µ–љ–Є—П —Б–∞–Љ–Є —А–∞–љ–ґ–Є—А—Г—О—В—Б—П –љ–∞ –Њ—Б–љ–Њ–≤–µ –≤—Л—Б–Њ—В—Л –≥–∞—А–Љ–Њ–љ–Є–Ї, —Б–Љ. –Ї–∞–Ї –≤—Л–≥–ї—П–і–Є—В –Љ–∞—Б—Б–Є–≤ Data.
–Ь–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–µ —Г—Е–Є—Й—А–µ–љ–Є—П –≤—Б–µ –ґ–µ –њ–Њ–ї–µ–Ј–љ—Л. –Э–∞–њ—А–Є–Љ–µ—А, –≤ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В –Њ—Ж–µ–љ–Є–≤–∞–µ—В—Б—П –∞–±—Б–Њ–ї—О—В–љ–Њ–µ —Б–Њ–≤–њ–∞–і–µ–љ–Є–µ –њ–Њ –≤—Б–µ–Љ —Н–ї–µ–Љ–µ–љ—В–∞–Љ. –Р –Ї—В–Њ —Б–Ї–∞–Ј–∞–ї, —З—В–Њ –љ–µ–ї—М–Ј—П –њ—А–Є–Љ–µ–љ–Є—В—М –Ї —А–∞–≤–љ–Њ–Љ–µ—А–љ—Л–Љ –Љ–∞—Б—Б–Є–≤–∞–Љ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ—Г—О —Д—Г–љ–Ї—Ж–Є—О, —А–µ–Ј—Г–ї—М—В–∞—В –ґ–µ –Њ—Д–Њ—А–Љ–Є—В—М –≤ —В–Њ–Љ –ґ–µ –Ї–ї–∞—Б—Б–µ TmemLevelSound.
–Х—Б–ї–Є –Љ–Є–љ–Є–Љ–∞–ї—М–љ–∞—П –Ј–∞–і–∞—З–∞ —Б—В–Њ–Є—В –Ї–∞–Ї —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ —Д–Њ–љ–µ–Љ, —В–Њ –≤ –і–∞–ї—М–љ–µ–є—И–µ–Љ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –Њ–±–і—Г–Љ–∞—В—М –Ї–∞–Ї –Њ—Д–Њ—А–Љ–Є—В—М —Б–ї–µ–і—Г—О—Й–Є–є —Г—А–Њ–≤–µ–љ—М —Б –њ–∞—А–∞–Љ–µ—В—А–Њ–Љ Size = 2. –≠–ї–µ–Љ–µ–љ—В–Њ–Љ –Љ–∞—Б—Б–Є–≤–∞ Data –≤ —Н—В–Њ–Љ —Б–ї—Г—З–∞–µ –±—Г–і—Г—В –љ–µ —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –Ї–∞–і—А–∞ —Б —Г–њ–∞–Ї–Њ–≤–∞–љ–љ—Л–Љ–Є –Ј–љ–∞—З–µ–љ–Є—П–Љ–Є, –∞ –Є–љ–і–µ–Ї—Б—Л –Љ–∞—Б—Б–Є–≤–∞ Data –љ–Є–ґ–љ–µ–≥–Њ —Г—А–Њ–≤–љ—П.
Lmem_sound[1].Data[n][k]:= (0,1),(2,0)вА¶(3,1); –≥–і–µ
0 вАУ —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –Љ–∞—Б—Б–Є–≤—Г (1372, 2324, 3615, 4894, 5926, 7295, 8577, 9602, 10632, 11130, 13085, 16651, 20237, 22552, 26120);
1 вАУ (271, 1409, 3863, 5162, 6480, 7467, 7986, 9177, 9853, 11338, 11796, 13077, 13843, 14860, 15632, 22027); —Б–Љ. –њ—А–Є–Љ–µ—А –Љ–∞—Б—Б–Є–≤–∞ Data.
–°—А–∞–≤–љ–µ–љ–Є—П —В–∞–Ї –ґ–µ –њ–Њ–љ—П—В–љ—Л, –∞ —Б–Њ—А—В–Є—А–Њ–≤–Ї–∞ –±—Г–і–µ—В –∞–љ–∞–ї–Њ–≥–Є—З–љ–Њ —В–Њ–Љ—Г, –Ї–∞–Ї —Д—А–∞–Ј–∞ ¬Ђ–Љ–∞–Љ–∞ –Љ—Л–ї–∞¬ї –Њ–њ–µ—А–µ–ґ–∞–µ—В —Д—А–∞–Ј—Г ¬Ђ–Љ–∞—И–∞ –Љ—Л–ї–∞¬ї.
–Ш —Н—В–Њ –µ—Й–µ –љ–µ –≤—Б—С, –њ—А–Њ–і–Њ–ї–ґ–µ–љ–Є–µ —Б–ї–µ–і—Г–µ—В...
–Э–µ–Ї–Њ—В–Њ—А—Л–µ —В–µ—Е–љ–Є—З–µ—Б–Ї–Є–µ –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В–Є.
–Я—А–Њ–≥—А–∞–Љ–Љ–∞ DFTV –љ–µ –∞–і–∞–њ—В–Є—А–Њ–≤–∞–љ–∞ –њ–Њ –±—Л—Б—В—А–Њ–і–µ–є—Б—В–≤–Є—О. –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П –≤ —А–µ–∞–ї—М–љ–Њ–Љ –Љ–∞—Б—И—В–∞–±–µ –≤—А–µ–Љ–µ–љ–Є –Љ–Њ–ґ–µ—В —В–Њ—А–Љ–Њ–Ј–Є—В—М –Ї–Њ–Љ–њ—М—О—В–µ—А. –Х—Б–ї–Є –њ–Њ—Б–Љ–Њ—В—А–µ—В—М –љ–∞ –†–Є—Б. 1 –≤ —Б—В–∞—В—Г—Б–љ–Њ–є —Б—В—А–Њ–Ї–µ –≤–љ–Є–Ј—Г —Б—В–Њ–Є—В —Ж–Є—Д—А–∞ 2012. –≠—В–Њ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –Љ–Њ–є –Ї–Њ–Љ–њ—М—О—В–µ—А —Б–њ—А–∞–≤–ї—П–µ—В—Б—П. –Х—Б–ї–Є –±—Г–і–µ—В —Ж–Є—Д—А–∞ –±–Њ–ї—М—И–µ 2500, –Љ–Њ–≥—Г—В –±—Л—В—М –њ—А–Њ–±–ї–µ–Љ—Л. –Ч–∞–њ–Є—Б—М –і–ї–Є—В—Б—П 2000 –Љ—Б, –Є–Ј-–Ј–∞ –≤—Л—З–Є—Б–ї–µ–љ–Є–є —Б–њ–µ–Ї—В—А–∞ –љ–∞–±–µ–≥–∞–µ—В –µ—Й–µ.
–Ь–∞—В–µ—А–Є–∞–ї—Л:
–Ю–±–Ј–Њ—А:
| ¬Ђ–Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Њ–Ї–Њ–љ–љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є –≤ –Ј–∞–і–∞—З–∞—Е —Ж–Є—Д—А–Њ–≤–Њ–≥–Њ —Б–њ–µ–Ї—В—А–∞–ї—М–љ–Њ–≥–Њ –∞–љ–∞–ї–Є–Ј–∞. –Я—А–Є–Љ–µ—А—Л –Є —А–µ–Ї–Њ–Љ–µ–љ–і–∞—Ж–Є–Є¬ї. –Ю—В–ї–Є—З–љ–∞—П —Б—В–∞—В—М—П. |
| ¬Ђ–Ъ–Њ–Љ–њ—М—О—В–µ—А–љ–Њ–µ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ –Є –њ–Њ—А–Њ–ґ–і–µ–љ–Є–µ —А–µ—З–Є¬ї |
|
¬Ђ–Ф–Є—Б–Ї—А–µ—В–љ–Њ–µ –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є–µ –§—Г—А—М–µ¬ї –С–∞-—Е—Г—Б—Б–µ–є–љ –Р.–Р. –Ш–Љ–µ–љ–љ–Њ –Ј–і–µ—Б—М —Д–Њ—А–Љ—Г–ї–∞ –і–ї—П –≤—Л—З–Є—Б–ї–µ–љ–Є—П –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–Њ–≤ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–∞ –љ–µ —З–µ—А–µ–Ј –Ї–Њ–Љ–њ–ї–µ–Ї—Б–љ—Г—О –њ–µ—А–µ–Љ–µ–љ–љ—Г—О, –Ї–Њ—В–Њ—А–∞—П —Б–ґ—Л—А–∞–µ—В –Љ–Њ–Ј–≥ –Є —А–µ—Б—Г—А—Б—Л –Ї–Њ–Љ–њ–∞, –∞ —З–µ—А–µ–Ј –Ї–ї–∞—Б—Б–Є—З–µ—Б–Ї–Є–є —Б–Є–љ—Г—Б –Є –Ї–Њ—Б–Є–љ—Г—Б! –Ъ–∞–Ї –Є –і–Њ–ї–ґ–љ–Њ –±—Л—В—М, –Є–±–Њ –≤—Б–µ —Н—В–Є –Љ–љ–Є–Љ—Л–µ —З–Є—Б–ї–∞ –і–ї—П –њ—Г—Й–µ–є —Г—З–µ–љ–Њ—Б—В–Є –≤–≤–µ–і–µ–љ—Л, –і–ї—П —Б–Њ–Є—Б–Ї–∞–љ–Є—П –Њ—З–µ–љ—М —Г—З–µ–љ—Л—Е —Б—В–µ–њ–µ–љ–µ–є... –Ш –љ–µ –љ–∞–і–Њ –Љ–љ–µ –≥–Њ–≤–Њ—А–Є—В—М –Њ —В–Њ–Љ, —З—В–Њ —П –љ–µ –ї—О–±–ї—О –Љ–∞—В–µ–Љ–∞—В–Є–Ї—Г. –Я—Г—Б—В—М —В–Њ—В, –Ї—В–Њ –Ј–љ–∞–µ—В —З—В–Њ —В–∞–Ї–Њ–µ –Љ–µ—В–Њ–і —Д—Г–љ–Ї—Ж–Є–Є –У—А–Є–љ–∞ –љ–∞–њ–Є—И–µ—В –Љ–љ–µ –њ–Є—Б—М–Љ–Њ. –§–Є–Ј–Є—З–µ—Б–Ї–Є–є —Б–Љ—Л—Б–ї –Ј–∞–±—Л–≤–∞—В—М –љ–µ–ї—М–Ј—П. –Т—Б–µ –≤ –Ь–Є—А–µ –µ—Б—В—М –Ї–Њ–ї–µ–±–∞–љ–Є—П, –Ї–Њ—В–Њ—А—Л–µ –Њ–њ–Є—Б—Л–≤–∞—О—В—Б—П —В—А–Є–≥–Њ–љ–Њ–Љ–µ—В—А–Є—З–µ—Б–Ї–Є–Љ–Є —Д—Г–љ–Ї—Ж–Є—П–Љ–Є, –∞ –њ—А–Њ—З–Є–µ —Б–Њ–Ј–і–∞–љ—Л —В–Њ–ї—М–Ї–Њ –і–ї—П —Г–і–Њ–±—Б—В–≤–∞, –Ї–∞–Ї –љ–∞–њ—А–Є–Љ–µ—А –њ—А–µ–Њ–±—А–∞–Ј–Њ–≤–∞–љ–Є—П –Ы–∞–њ–ї–∞—Б–∞. –•–∞—Г, —П –≤—Б—С —Б–Ї–∞–Ј–∞–ї... |
[1] https://www.google.com/intl/en/chrome/demos/speech.html - —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ –≥–Њ–ї–Њ—Б–∞ –≤ Google.
[2] http://www.speechpro.ru/ - –¶–µ–љ—В—А –†–µ—З–µ–≤—Л—Е –Ґ–µ—Е–љ–Њ–ї–Њ–≥–Є–є.
[3] http://www.keklab.ru/buf/ai/psychoacoustics.pdf - –Ш—А–Є–љ–∞ –Р–ї–і–Њ—И–Є–љ–∞ ¬Ђ–Ю—Б–љ–Њ–≤—Л –њ—Б–Є—Е–Њ–∞–Ї—Г—Б—В–Є–Ї–Є¬ї.
[4] http://websound.ru/articles/theory/fft.htm - ¬ЂFFT –∞–љ–∞–ї–Є–Ј¬ї, –Р–≤—В–Њ—А: –Ф–Љ–Є—В—А–Є–є –Ь–Є—Е–∞–є–ї–Њ–≤.
http://prosound.ixbt.com/education/spektr-analys.shtml - ¬Ђ–°–њ–µ–Ї—В—А–Њ–∞–љ–∞–ї–Є–Ј–∞—В–Њ—А вАУ —З—В–Њ –Љ—Л –љ–∞ –љ–µ–Љ –≤–Є–і–Є–Љ?¬ї –Р–ї–µ–Ї—Б–µ–є –Ы—Г–Ї–Є–љ.
http://forum.sources.ru/index.php?showtopic=145994 вАУ —Д–Њ—А—Г–Љ ¬Ђ–Ш—Б—Е–Њ–і–љ–Є–Ї–Є.RU. –Ґ–µ–Љ–∞ –њ–Њ—Б–≤—П—Й–µ–љ–∞ —Д–Њ–љ–µ–Љ–љ–Њ–Љ—Г —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—О —А–µ—З–Є.
[5] http://ru.wikipedia.org/wiki/%CA%EE%F0%F0%E5%EB%FF%F6%E8%FF вАУ –Љ–∞—В–µ—А–∞–ї –Т–Є–Ї–Є –Њ –Ї–Њ—А—А–µ–ї—П—Ж–Є–Њ–љ–љ–Њ–є —Д—Г–љ–Ї—Ж–Є–Є –Я–Є—А—Б–Њ–љ–∞.
[6] http://www.phviewer.ru/article/o-kepstralnom-analize-v-popularnoj-forme - –Њ—З–µ–љ—М —Е–Њ—А–Њ—И–∞—П —Б—В–∞—В—М—П "–Ю –Ї–µ–њ—Б—В—А–∞–ї—М–љ–Њ–Љ –∞–љ–∞–ї–Є–Ј–µ –≤ –њ–Њ–њ—Г–ї—П—А–љ–Њ–є —Д–Њ—А–Љ–µ"–°—Г–≤–Њ—А–Њ–≤ –Т.–Э., "–Т–Є –Ґ—Н–Ї", –°–∞–љ–Ї—В.–Я–µ—В–µ—А–±—Г—А–≥, –†–Њ—Б—Б–Є—П. –Ю—В —Б–µ–±—П –і–Њ–±–∞–≤–ї—О, —З—В–Њ –љ–µ –љ–∞–і–Њ —Б–ґ–Є–Љ–∞—В—М ZIP-–Њ–Љ JPG - —Д–∞–є–ї.
[7] http://zhurnal.ape.relarn.ru/articles/2003/148.pdf - ¬Ђ–†–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ —А–µ—З–µ–≤—Л—Е —Б–Є–≥–љ–∞–ї–Њ–≤ –љ–∞ –Њ—Б–љ–Њ–≤–µ –Љ–µ—В–Њ–і–∞ –Њ–±–µ–ї—П—О—Й–µ–≥–Њ —Д–Є–ї—М—В—А–∞¬ї –С–Њ—З–∞—А–Њ–≤ –Ш.–Т.( –≠—В–Њ—В e-mail –∞–і—А–µ—Б –Ј–∞—Й–Є—Й–µ–љ –Њ—В —Б–њ–∞–Љ-–±–Њ—В–Њ–≤, –і–ї—П –µ–≥–Њ –њ—А–Њ—Б–Љ–Њ—В—А–∞ —Г –Т–∞—Б –і–Њ–ї–ґ–µ–љ –±—Л—В—М –≤–Ї–ї—О—З–µ–љ Javascript ), –Р–Ї–∞—В—М–µ–≤ –Ф.–Ѓ.
[8] http://security-corp.org/os/linux/2986-filtr-kalmana-vvedenie.html - ¬Ђ–§–Є–ї—М—В—А –Ъ–∞–ї–Љ–∞–љ–∞ вАФ –Т–≤–µ–і–µ–љ–Є–µ¬ї. –Ґ–Њ–ї—М–Ї–Њ –њ–Њ—Б–ї–µ —Н—В–Њ–є —Б—В–∞—В—М–Є —Б—В–∞–ї–Њ –њ–Њ–љ—П—В–љ–Њ, —З—В–Њ —Н—В–Њ —В–∞–Ї–Њ–µ.
–Ю–±–љ–Њ–≤–ї–µ–љ–Њ (19.06.2013 07:09)
